Review: Evolutionary Algorithms
Basics
Searching Big Search Spaces
- Search space: \(\{0, 1\}^n\).
- $2^n$ possible candidates.
- Assume \(\mathbf{a}^*\in \{0, 1\}^n\) is the goal vector.
- Size (formally called the cardinality) of the binary search space: \(\vert \{0, 1\}^n \vert = 2^n\) . It is growing exponentially.
- The following objective function $f(\mathbf{x}) = \sum_{i = 1}^n x_i$ is called OneMax or CountingOnes, which is of fundamental importance in the theory of evolutionary algorithms.
Monte-Carlo Search
\begin{algorithm}
\caption{Monte-Carlo Search}
\begin{algorithmic}
\STATE $k\leftarrow 1$
\STATE Randomly initialize a candidate solution $\mathbf{a}_k\in\{0, 1\}^n$.
\WHILE{$\mathbf{a_k} \neq \mathbf{a}^*$}
\STATE $k \leftarrow k + 1$
\STATE Random generate a new candidate $\mathbf{a}_k\in\{0, 1\}^n$
\ENDWHILE
\end{algorithmic}
\end{algorithm}
Why Monte-Carlo search is inefficient?
Intuition: identical strings might be tested repeatedly.
Proof 1
$p_k$: the probability of generating $\mathbf{a}^*$ in the first $k$ iterations.
Use $\ln (1 + x) \approx x$ for $x \approx 0$,
\[\begin{align*} k &\approx -2^n\ln (1 - p_k) \end{align*}\]Monte-Carlo search performs worse than the complete enumeration:
\[\begin{align*} -2^n \ln (1 - p_k) &\geq 2^n\\ p_k > 1 - \frac{1}{e} &\approx 0.63 \end{align*}\]Proof 2
From the perspective of the geometric distribution:
\[\begin{align*} p &= P\{\mathbf{a}_1 = \mathbf{a}^*\} = \frac{1}{2^n} \\ p_k &= (1 - p)^{k - 1}p\\ E[k] &= \sum_{k = 1}^{\infty} k\cdot p_k\\ &= \sum_{k = 1}^{\infty} k\cdot (1 - p)^{k - 1}p\\ &= \frac{1}{p} \\ &= 2^n \end{align*}\]The expected running time is exponential on average.
\[\begin{align*} Pr(k > 2^n) &= 1 - \sum_{k = 1}^{2^n} p_k = \left(1 - 2^{-n}\right)^{2^n} \end{align*}\]Let $c = 2^n$. Use the limit $\lim_{x\rightarrow \infty}\ln \left(1 - \frac{1}{x} \right)^n = -1$,
\[Pr(k > 2^n) = \exp\left[\ln\left(1 - \frac{1}{c}\right)^c \right] \rightarrow e^{-1} \approx 0.3679\]Evolutionary Search
Evolutionary algorithms is not Monte-Carlo search.
\begin{algorithm}
\caption{Evolutionary Search}
\begin{algorithmic}
\STATE $k \leftarrow 1$
\STATE Randomly initialize a candidate solution $\mathbf{a}_k \in\{0,1\}^n$.
\WHILE{$\mathbf{a}_k \neq \mathbf{a}^*$}
\STATE Create a copy $\mathbf{a}_k^{\prime}$ of $\mathbf{a}_k$.
\STATE Flip each bit in $\mathbf{a}_k^{\prime}$ with probability $p \in(0,1)$.
\IF{$d\left(\mathbf{a}_k^{\prime}, \mathbf{a}^*\right) < d\left(\mathbf{a}_k, \mathbf{a}^*\right)$}
\COMMENT{$d(a, b)$ computes the Hamming Distance.}
\STATE $\mathbf{a}_{k+1} \leftarrow \mathbf{a}_k^{\prime}$
\ELSE
\STATE $\mathbf{a}_{k+1} \leftarrow \mathbf{a}_k$
\ENDIF
\STATE $k \leftarrow k+1$
\ENDWHILE
\end{algorithmic}
\end{algorithm}
Algorithm analysis
Assume exactly $m$ bits are still wrong.
Assume we need $n\ 1$-bit improvements. Use $\lim_{n \rightarrow \infty}\left(\sum_{k=1}^n \frac{1}{k}-\ln n\right)=\gamma=0.522$:
\[\begin{align*} E_{\text {iter }}(n) &\leq \frac{\ln n}{p(1-p)^{n-1}} + \gamma\\ \end{align*}\]Assuming $p=\frac{q}{n}$ with an integer $q$. Use $\lim_{n \rightarrow \infty}\left(1+\frac{x}{n}\right)^n=e^x$:
\[E_{\text {iter }}(n)<\frac{e^q}{q} n \ln n \Rightarrow E_{\text {iter }}(n) \in O(n \ln n)\]Remarks
- For this simple example: evolution-like algorithms are logarithmic, not exponential, concerning their running time.
- The analysis of Algorithm 2 is oversimplified:
- Only one-bit mutations.
- Only improving mutations.
- Only an upper bound on $E(n)$.
- We can assume to start with $n/2$ correct bits.
- Algorithm 2 is a so-called $(1+1)$-algorithm.
Optimization
Definition
| Approach | Input | Model | Output |
|---|---|---|---|
| Modeling | $\checkmark$ | $?$ | $\checkmark$ |
| Simulation | $\checkmark$ | $\checkmark$ | $?$ |
| Optimization | $?$ | $\checkmark$ | $\checkmark$ |
Given the objective function $f: M\rightarrow \mathbb{R}$, the optimization goal is $\min f(\mathbf{x})$.
- $f$: objective function.
- High-dimensional.
- Non-linear, multimodal.
- Discontinuous, noisy, dynamic.
- $M\subseteq M_1\times M_2\times \cdots\times M_n$ is heterogeneous.
- Restrictions possible over $M, f(x)$.
- Good global / local, robust optimum desired.
Remarks
- Evolutionary Algorithms (EAs) are mostly used for optimization.
- EAs are global random search algorithms.
- Global: find the global optimum (in the long run).
Terminology
- Classification of optimization algorithms.
- Direct optimization algorithms: evolutionary algorithms.
- First-order optimization algorithms: gradient methods.
- Second-order optimization algorithms: quasi-Newton methods.
- Black-box optimization: the analytical form of the optimization problem is unknown, e.g. simulation models, real-life experiments.
- Hamming distance: $\delta_H (\mathbf{x}, \mathbf{y}) = \sum_{i} I(x_i\neq y_i) = \sum_{i} \vert x_i - y_i\vert $.
Theoretical statements for EA
Global convergence with probability 1.
\[Pr\left(\lim_{t\rightarrow \infty} \mathbf{x}_t\in X^* \right) = 1\]where \(\{\mathbf{x}_1, \mathbf{x}_2, \dots\}\) is the sequence of all points generated by the algorithm and $X^*$ is the set of global optimizer.
- General statement holds for all functions with a measurable size of the set of global maximizers.
- Useless for practical situations:
- Time plays a major role in practice.
- Not all objective functions are relevant in practice.
Convergence velocity:
\[\varphi = E\left[f_{\text{best}}^{t+1} - f_{\text{best}}^{t} \right]\]- Typically, convex objective functions.
- Very extensive results available for evolution strategies and genetic algorithms.
- Not all objective functions are relevant in practice.
An infinite number of pathological cases.
- No Free Lunch (NFL) theorem: all optimization algorithms perform equally well iff performance is averaged over all possible optimization problems.
- Fortunately,we are not interested in “all possible optimization problems”.
Introduction to EAs
EAs taxonomy: genetic algortims (GA), evolution strategies (ES), evolutionary programming (EP), and genetic programming (GP).
GA vs ES
| Genetic Algorithms | Evoluntion Strategies |
|---|---|
| Discrete representations | Mixed-integer capabilities |
| Emphasis on crossover | Emphasis on mutation |
| No self-adaptation | Self-adaptation |
| Larger population sizes | Small population sizes |
| Probabilistic selection | Deterministic selection |
| Developed in US | Developed in Europe |
| Theory focused on schema processing | Theory focused on convergence speed |
Overview of EAs
- Main components.
- Representation of individuals: coding.
- Evaluation method for individuals: fitness.
- Variation operators: mutation and crossover.
- Selection mechanism: parent (mating) selection mechanism and survivor (environmental) selection mechanism.
- Advantages.
- Widely applicable, also in cases where no good solution techniques are available.
- Multimodalities, discontinuities, constraints.
- Noisy objective functions.
- Multiple criteria decision making problems.
- Implicitly defined problems (simulation models).
- No presumptions with respect to search space.
- Low development costs, i.e., costs to adapt to new problems.
- The solutions of EAs have straightforward interpretations.
- Can run interactively, always deliver solutions.
- Self-adaptation of strategy parameters.
- Widely applicable, also in cases where no good solution techniques are available.
- Disadvantages.
- No guarantee for finding optimal solutions within a finite amount of time. This is true for all global optimization methods.
- No complete theoretical basis (yet), but much progress is being made.
- Parameter tuning is sometimes based on trial and error. Solution: self-adaptation of strategy parameters.
- Two views.
- Global random search methods.
- Probabilistic search with high “creativity”.
- Diversified search.
- Applying local search operators.
- Nature-based search techniques.
- Stochastic influence.
- Population based.
- Adaptive behavior.
- Recognizing / amplifying strong gene patterns.
- Global random search methods.
Asymptotic Notations
Assume $T (n)$ and $g(n)$ are both defined on $\mathbb{N}>0$ and take value in \(\mathbb{R} >0 \cup \{\infty\}^1\).
- Big-O notation ($T (n)$ is bounded above) describes the worst case of the running time of an algorithm. We say the running time of an algorithm is $T (n) \in O(g(n))$ if there $\exists n_0 > 0$ and $C > 0$ such that $\forall n > n_0 , T (n) \leq Cg(n)$. Equivalently, $T(n)\in O(g(n)) \Leftrightarrow \limsup_{n\rightarrow \infty} \frac{T(n)}{g(n)} < \infty$.
- Big-Omega notation ($T (n)$ is bounded below, Knuth’s definition) describes the best case of running time of an algorithm. We say $T (n) \in \Omega (g(n))$ if there exists if there $\exists n_0 \geq 0$ and $c > 0$ such that $\forall n > n_0$, $T (n) \geq cg(n)$. Equivalently, $T (n) \in \Omega (g(n)) \Leftrightarrow \liminf_{n\rightarrow\infty} \frac{T(n)}{g(n)}> 0$.
- Big-Theta notation ($T (n)$ is bounded above and below). We say $T (n) \in \Theta (g(n))$ if there $\exists n_0 > 0, c_1 > 0$, and $c_2 > 0$ such that $\forall n > n_0 , c_1 g(n) \leq T (n) \leq c_2 g(n)$. Equivalently, $T (n) \in \Theta(g(n))$ iif $T (n) \in O(g(n))$ and $T (n) \in \Omega (g(n))$.
- Small-O notation ($T (n)$ is dominated asymptotically). We say $T (n) \in o(g(n))$ if $\forall C > 0$ there $\exists n_0 > 0$ such that $\forall n > n_0$, $T (n) < Cg(n)$, meaning $T (n)$ grows way slower than $g(n)$. Equivalently, $T (n) \in o(g(n)) \Leftrightarrow \lim_{n\rightarrow \infty} \frac{T(n)}{g(n)} = 0$.
- Small-Omega notation ($T (n)$ is dominating asymptotically). We say $T (n) \in \omega (g(n))$ if $\forall C > 0$ there $\exists n_0 > 0$ such that $\forall n > n_0 , T (n) > Cg(n)$, meaning $\lim T (n)$ grows way faster than $g(n)$. Equivalently, $T (n) \in \omega (g(n)) \Leftrightarrow \lim_{n\rightarrow \infty} \frac{T(n)}{g(n)} = \infty$.
- The same order (asymptotically equal). We say $T(n) \sim g(n)$ if $\forall \varepsilon > 0$ there $\exists n_0 > 0$ such that $\forall n > n_0$, $\vert T(n)/g(n) − 1\vert < \varepsilon$. Equivalently, $T (n)\sim \lim_{n\rightarrow\infty} \frac{T(n)}{g(n)} = 1$.
Genetic Algorithms
Overview
\begin{algorithm}
\caption{Genetic Algorithm}
\begin{algorithmic}
\STATE $t \leftarrow$ 0
\STATE \texttt{Initialization}$(P(t))$
\STATE \texttt{Evaluation}$(P(t))$
\WHILE{Termination criterion not met}
\STATE $P(t)_{\text{temp}} \leftarrow$ \texttt{MatingSelection}$(P(t))$
\STATE $P(t)_{\text{temp}} \leftarrow$ \texttt{Crossover}$(P(t)_{\text{temp}}, p_c)$
\STATE $P(t)_{\text{temp}} \leftarrow$ \texttt{Mutation}$(P(t)_{\text{temp}}, p_m)$
\STATE \texttt{Evaluation}$(P(t))$
\STATE $P(t + 1)\leftarrow P(t)_{\text{temp}}$
\STATE $t \leftarrow t + 1$
\ENDWHILE
\end{algorithmic}
\end{algorithm}
Main features
- Often binary search space \(\{0, 1\}^l\).
- Emphasis on crossover (recombination).
- No environmental selection. Probabilistic mating selection (proportional etc.).
- Constant strategy parameters.
Representation
Genotype / Phenotype Space
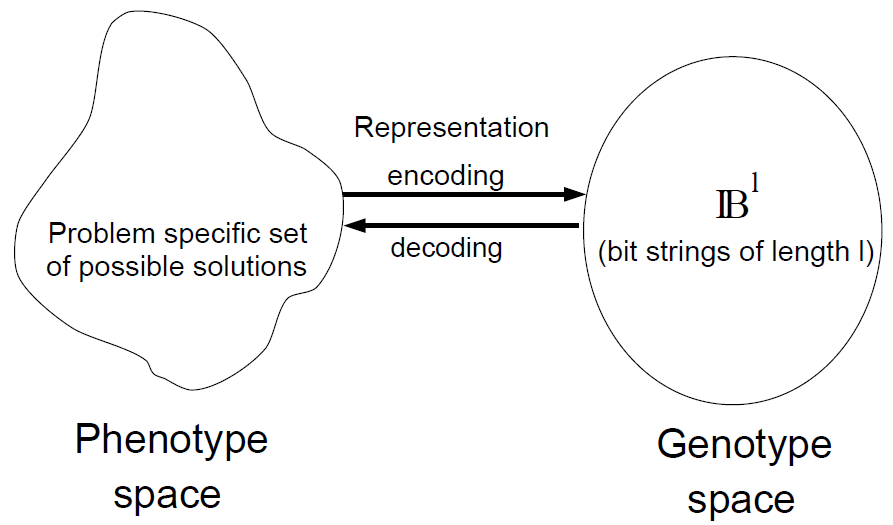
Remarks
- Canonical GAs: individuals \(\mathbf{a}\in\{0, 1\}^l\).
- Genotype space: \(\{0, 1\}^l\).
- Problem-specific representation (phenotype space) mapped to \(\{0, 1\}^l\) decoding and encoding functions.
- Variation operators act on genotypes. Selection acts on phenotype evaluations.
- Phenotypes are evaluated. Genotypes are decoded into phenotypes.
Mapping Real Numbers
Solve a problem defined over real values:
- Subdivide $\mathbf{a}$ into $n$ segments of equal length.
- Decode each segment into integer value.
- Map each integer linearly into a given real-valued interval.
Key points
- Phenotype space: $M = \prod_{i = 1}^n[u_i, v_i]\subseteq \mathbb{R}^n$ with interval bounds $u_i < v_i$
- Genotype space: \(\{0, 1\}^l\) with $l = n\cdot l_x$.
Decoding function: \(h^{\prime}(\mathbf{a})=\left[h_1\left(a_1, \ldots, a_{l_x}\right), h_2\left(a_{1+l_x}, \ldots, a_{2 l_x}\right), \ldots, h_n\left(a_{1+(n-1) l_x}, \ldots, a_l\right)\right]\) with (like little-endian).
\[\begin{align*} a_1^{\prime}, a_2^{\prime}, \ldots, a_{l_x}^{\prime} & =a_{1+(i-1) l_x}, a_{2+(i-1) l_x}, \ldots, a_{l+(i-1) l_x} \\ h_i\left(a_1^{\prime}, \ldots, a_{l_x}^{\prime}\right) & =u_i+\frac{v_i-u_i}{2^{l_x}-1}\left(\sum_{k=0}^{l_x - 1} a_{l_x - k}\cdot 2^{k}\right) \end{align*}\]Example:
Assume $u_i = -50, v_i = 50, l_x = 9$ bits used to represent \(\{0, 1, \dots, 511\}\).

- $100110100 \rightarrow 2^0 + 2^3 + 2^4 + 2^6 = 89 \rightarrow -50 + \frac{100}{511}\times 89 \approx -32.5831$.
- $111011110 \rightarrow 2^0 + 2^1 + 2^2 + 2^4 + 2^5 + 2^6 + 2^7 = 247 \rightarrow -50 + \frac{100}{511}\times \approx -1.6634$.
Binary Code
- Convert a decimal number to binary is to divide the number by 2 and round down to the nearest integer.
- Convert a binary number to decimal is to multiply the number by 2 and add the result, i.e., $\sum_{i=0}^{l - 1} d_i \cdot 2^i$. For example, \(1010_2\rightarrow 2^3 + 2^1 = 10_{10}\).
Gray Code
- Gray code is a binary code in which two successive codewords differ in only one bit.
Assume the binary code of a string is $(b_{n - 1}\dots b_0)$ and its gray code is $g_n\dots g_1$. We have the following relationship:
\[\begin{align*} g_i &= b_i \oplus b_{i - 1}\\ b_{i - 1} &= b_i \oplus g_i \end{align*}\]Example: bitstring 1011.
- Binary decoding: $2^0 + 2^1 + 2^3 = 11$.
Gray decoding:
\[\begin{align*} & 1\quad 0\quad 1\quad 1\\ & 0\quad 1\quad 0\quad 1\\ & 0\quad 0\quad 1\quad 0\\ \oplus\quad & 0\quad 0\quad 0\quad 1\\ \hline &1\quad 1\quad 0\quad 1 \end{align*}\]$2^3 + 2^2 + 2^0 = 13$
- If the binary code is 1011, the corresponding gray code is 1110 ($14_{10}$).
Selection
Proportional Selection
Implementation: roulette wheel technique.
- Assign to each individual a part of the roulette wheel (size proportional to its fitness).
- Spin the wheel $\mu$ times to select $\mu$ individuals.
Naive version
\[p_i = \frac{f_i}{\sum_{j = 1}^\mu f_j}\]Disadvantages
- Functions $f$ and $f + c$ with constant $c$ handled differently.
- If all function values in a population are similar $\Rightarrow$ random selection.
- Require positive-values, maximization.
- Need the population size $\mu$.
Scaling version
Let $c = f_{\min}$,
- Scaling increases selection probabilities of above-average individuals.
- Decrease selection probabilities of below-average individuals.
- Improved version: shift the values by slightly more than the smallest value to have all probabilities above 0, e.g., $f’ = f - c + 0.1$.
Rank Selection
In rank selection, the selection probability does not depend directly on the fitness, but on the fitness rank of an individual within the population.
- This puts large fitness differences into perspective.
- The exact fitness values themselves do not have to be available, but only a sorting of the individuals according to quality.
Example: a rank-based function,
\[\phi(\mathbf{a}) = \frac{2r_i}{\mu(\mu + 1)}\]where $r_i$ is the rank of the $i$-th individual’s fitness value $f_i$ in the population.
Tournament Selection
Assume the tournament size is $k$.
Version 1
- Select $k$ individuals from the population and perform a tournament amongst them.
- Select the best individual from the $k$ individuals.
- Repeat process 1 and 2 until you have the desired amount of population.
Version 2
- Select $k$ individuals from the population at random.
- Choose the $i$-th best individual with probability $p\cdot(1-p)^i$.
- Repeat process 1 and 2 until you have the desired amount of population.
Crossover
One-point Crossover
- Choose a random point on the two parents.
- Split parents at this crossover point.
- Create children by exchanging tails
$n$-point Crossover
- Choose $n$ random crossover points.
- Split along those points.
- Glue parts, alternating between parents.
Uniform Crossover
- For each \(i\in\{1, \dots, l\}\), flip a coin.
- If “head”, copy bit from Parent 1 to Offspring 1, Parent 2 to Offspring 2.
- If “tail”, copy bit from Parent 1 to Offspring 2, Parent 2 to Offspring 1.
Crossover Parameters
- Application probability $p_c\in[0, 1]$. Chooses two individuals with probability $p_c$ for crossover.
- Number of crossover points $z$.
Partially Mapped Crossover (PMX)
For traveling salesman problem (TSP) like problems.
- Selection of two crossover points.
- Copy the middle segment.
- Determine mapping relationship to legalize offspring.
- Legalize offspring with the mapping relationship.
An example from Baeldung post:
Step 1.
\[\begin{align*} \text{Parent 1} &= (1, 2, \underline{3, 4, 5, 6}, 7, 8, 9)\\ \text{Parent 2} &= (5, 4, \underline{6, 9, 2, 1}, 7, 8, 3) \end{align*}\]Step 2.
\[\begin{align*} \text{Offspring 1} &= (1, 2, \underline{6, 9, 2, 1}, 7, 8, 9)\\ \text{Offspring 2} &= (5, 4, \underline{3, 4, 5, 6}, 7, 8, 3) \end{align*}\]Step 3.
| Offspring 1 | Offspring 2 | |||
|---|---|---|---|---|
| 1 | $\leftrightarrow$ | 6 | $\leftrightarrow$ | 3 |
| 2 | $\leftrightarrow$ | 5 | ||
| 9 | $\leftrightarrow$ | 4 |
Step 4.
\[\begin{align*} \text{Offspring 1} &= (3, 5, \underline{6, 9, 2, 1}, 7, 8, 4)\\ \text{Offspring 2} &= (2, 9, \underline{3, 4, 5, 6}, 7, 8, 1) \end{align*}\]Order Crossover (OX1)
For order-based permutation tasks.
- Randomly select gene segments in $P_0$.
- As a child permutation, a permutation is generated that contains the selected gene segments of $P_0$ in the same position.
- The remaining missing genes are now also transferred, but in the order in which they appear in $P_1$.
- This results in the completed child genome.
An example from Wikipedia:
Step 1.
\[\begin{align*} \text{Parent 1} &= (\underline{1, 2}, 3, 4, 5, \underline{6, 7, 8}, 9,10)\\ \text{Parent 2} &= (2, 4, 1, 8, 10, 3, 5, 7, 6, 9) \end{align*}\]Step 2.
\[\text{Offspring} = (\underline{1, 2}, ?, ?, ?, \underline{6, 7, 8}, ?, ?)\]Step 3.
\[\begin{align*} P_\text{missing} &= (3, 4, 5, 9,10)\\ P_\text{in order from Parent 2} &= (4, 10, 3, 5, 9) \end{align*}\]Step 4.
\[\text{Offspring} = (\underline{1, 2}, 4, 10, 3, \underline{6, 7, 8}, 5, 9)\]Mutation
Bit-flip mutation
- Alter each gene with probability $p_m$.
- The standard choice is $p_m = 1 / l$.
- Only values of $1 / l \leq p_m \leq 1 / 2$ make sense.
- At least one bit on average should mutate.
- $p = 1/2$ corresponds with random generation of offspring.
Crossover or mutation?
- Cooperation and competition between exploration and exploitation.
- Exploration: discovering promising areas in the search space, i.e., gaining information on the problem.
- Exploitation: optimizing within a promising area, i.e., using information.
- If we define “distance in the search space” as Hamming distance:
- Crossover is explorative, it makes a big jump to an area somewhere “in between” two (parent) areas.
- Mutation is exploitative, it creates random small deviations, thereby staying near (i.e., in the area of) the parent.
- To hit the optimum you often need a “lucky” mutation (or multiple mutations).
Mutation and small deviations
- Assumptions
- Binary representations and decoding function $h(a_1, \dots, a_l) = \sum_{i = 0}^{l - 1} a_{i + 1}\cdot 2^i$ are used.
- Mutation with $p_m = 1/l$ is applied.
- Objective function $f = h$.
Results.
\[\begin{align*} P(\vert \Delta f\vert = 2^i) &= \frac{1}{l},\quad \forall i\in \{0, \dots, l - 1\} \\ \Delta f = f(\mathbf{a}) &- f(\mathbf{a}') = h(\mathbf{a}) - h(\mathbf{a}') \end{align*}\]- $\mathbf{a}$: parent individual.
- $\mathbf{a}’$: result of mutating $\mathbf{a}$.
Schema Theory
Schema
Definition
A schema $H\in\mathbb{B}^l$ is a partial instantiation of a string. Usually the uninstantiated elements are denoted by “$*$”, sometimes called “don’t care” symbol or “wild card”. A schema defines a subset of \(\mathbb{B}^l: H\in \{0, 1, *\}\).
Set of all instances of schema $H = (h_1, \dots, h_l)$:
\[I(H) = \{(a_1, \dots, a_l)\in\mathbb{B}^l|h_i\neq \ast \Rightarrow a_i = h_i\}\]Order of the schema: number of instantiated elements.
\[o(H) = \vert\{i|h_i\in\{0, 1\} \}\vert\]Length of the schema: length of the substring starting at the first and ending at the last instantiated element.
\[d(H) = \max\{i|h_i\in\{0, 1\}\} - \min\{i|h_i\in\{0, 1\}\}\]- Facts.
- In total there are $3^l$ different schemata.
Each chromosome (element of $\mathbb{B}^l$) is an instance of $2^l$ different schemata (examine the total number of schemata of which this element is an instance).
\[\begin{align*} \binom{l}{0} + \binom{l}{1} + \binom{l}{2} + \cdots + \binom{l}{l} &= \sum_{i = 0}^l \binom{l}{i}\\ &= \sum_{i = 0}^l \binom{l}{i} \cdot 1^i\\ &= 2^l \end{align*}\]- There are at most $\mu\cdot 2^l$ schemata represented in a population of size $\mu$.
- A schema can be viewed as a hyperplane of an $l$-dimensional space.
Schema Theorem
| Notation | Meaning |
|---|---|
| $f$ | to be maximized |
| $\bar{f}$ | mean fitness in population |
| $l$ | length of the string |
| $H$ | a schema |
| $d(H)$ | defining length |
| $o(H)$ | order of the schema |
| $p_m$ | mutation rate |
| $p_c$ | crossover rate |
| $f(H)$ | (estimated) schema fitness |
| $m(H, t)$ | expected number of instantiations of $H$ in generation $t$ |
Expected number of instantiations of $H$ selected for crossover:
\[m(H, t) \cdot \frac{f(H)}{\bar{f}}\]Probability that crossover does not occur within the defining length:
\[1-p_c \frac{d(H)}{l-1}\]Probability that the schema is not mutated:
\[\left(1-p_m\right)^{o(H)}\]The schema function inequality uses “$\geq$” because schema instances can appear from the crossover and the mutation of other patterns.
Exponential growth of building blocks
- Assumptions.
- $H$ is a short, low-order, highly fit schema.
- $f(H) > \bar{f}$ assumed: $f(H) = \bar{f} + c$.
- Assume $H$ is not destroyed by crossover or mutation.
- Assume this remains valid for a number of generations.
Equation \eqref{eq:st} can be simplified to:
\[m(H, t + 1) = m(H, t)\cdot \frac{\bar{f} + c}{\bar{f}} = m(H, t)\cdot (1 + c')\]For a number of generations:
\[m(H, t) = m(H, 0)\cdot (1 + c')^t\]- Exponential growth of $H$ in the population.
Criticism
- Most of Holland’s approximations are only true for very large numbers (trials and population size).
- Within finite populations, exponentially increasing the number of schema instances leads to entirely filling the population.
- Within finite populations, exponentially decreasing the number of schema instances leads to complete elimination.
- Not all schemata are represented in a typical population.
- Schemata of large defining length are likely to be destroyed by crossover (even highly fit ones).
Almost sure covergence
- Prerequisites.
- $\max_{\mathbf{x}\in P(t)} f(\mathbf{x}) \geq \max_{\mathbf{x}\in P(t - 1)} f(\mathbf{x})$, e.g., through elitist selection.
- Any point is accessible from any other point (i.e., with mutation $p_m > 0$).
Theorem.
\[\lim_{t\rightarrow \infty} Pr\{\mathbf{x}^*\in P(t)\} = 1\]- $P(t)$: population at time $t$.
- $\mathbf{x}^*$: global optimum.
Implicit Parallelism
- A lot of different schemata are effectively processed in parallel by a Genetic Algorithm. Individuals are instantiations of more than one schema.
- Effectively processing of a schema: reproduced at the desirable exponentially increasing rate.
- Why wouldn’t a schema be processed effectively?
- Reason: schema disruption by genetic operators.
- Holland’s estimate: $O(\mu^3)$ schemata are processed effectively when using a population of size $\mu$.
The Building Block Hypothesis (BBH)
- GAs are able to detect short, low order, and highly fit schemata and combine these into highly fit individuals.
- Building blocks are schemata that have:
- A small defining length, $d(H)$.
- Low order, $o(H)$.
- High estimated fitness, $f(H)$.
- Implicit parallelism and the BBH were seen as explanations for the power of GAs.
Convergence Velocity
Definition
Success probability:
\[p_{\vec{a}}^+ = P\{f(m(\vec{a})) > f(\vec{a}) \}\]$k$-step success probability ($0\leq k \leq k_{\max}$):
\[p_{\vec{a}}^+ = P\{f(m(\vec{a})) = f(\vec{a}) + k \}\]Convergence velocity:
\[\begin{align*} \varphi &= E\left[f_{\max}(P(t + 1)) - f_{\max}(P(t)) \right] \\ \Rightarrow \varphi_{1 + 1}(l, \vec{a}, p) &= \sum_{k = 0}^{k_{\max}} k\cdot p_{\vec{a}}^+ (k) \end{align*}\]Notation Meaning $l$ bit-string length $\vec{a}$ current parent $p$ mutation rate $k$ improvement, $k\geq 0$ because of $(1+1)$ $p_{\vec{a}}^+$ probability to get $k$ improvement
Counting Ones
Objective function:
\[f(\vec{a}) = \sum_{i = 1}^{l} a_i\]Assume $(1 + 1)$-GA with mutation rate $p$. Let $q = 1 - p$ and $f_a:=f(\vec{a})$:
\[\begin{align*} p_{\vec{a}}^0 &= \sum_{i = 0}^{\min\{f_a, l - f_a \}} \binom{f_a}{i}\binom{l - f_a}{i} p^{2i}q^{l - 2i}\\ p_{\vec{a}}^+(k) &= \sum_{i = 0}^{\min\{f_a, l - f_a - k \}} \binom{f_a}{i}\binom{l - f_a}{i + k} p^{2i + k}q^{l - 2i - k},\quad 0\leq k \leq l - f_a \\ p_{\vec{a}}^-(k) &= \sum_{i = 0}^{\min\{f_a - k, l - f_a \}} \binom{f_a}{i + k}\binom{l - f_a}{i} p^{2i + k}q^{l - 2i - k},\quad 0\leq k\leq f_a\\ \varphi_{(1+1)} &= \sum_{k = 0}^{l - f_a} k\cdot p_{\vec{a}}^+(k) \end{align*}\]Notation Meaning $f_a$ $f(\vec{a})$, the fitness value, the number of 1s $l$ the length of the bitstring $l - f_a$ the number of 0s $i$ the number of $1\rightarrow 0$ / $0\rightarrow 1$ $k$ $k$-step improvements (decline) $0 \rightarrow 1$ ($1 \rightarrow 0$) Approximated optimum mutation rate as a function of $f_a$:
\[\begin{align*} p^* \approx \frac{1}{2(f_a + 1) - l} \end{align*}\]- Absorption time.
- Define $1 + 1$ states: \(z_k = \{\vec{a}: f(\vec{a}) =l - k \}\quad (0\leq k\leq l)\), which represent solutions with $k$ zeros.
Transition probabilities
\[\begin{align*} p_{i j}&=P\{f(m(\vec{a}))=l-j \mid f(\vec{a})=l-i\}: \\ p_{i j}&=\left\{\begin{array}{lll} p_{l-i}^{+}(i-j) & , i>j & \text { Improvement } \\ 1-\sum_{k=1}^j p_{l-i}^{+}(k) & , i=j & \text { Stagnation } \\ 0 & , i<j & \text { Worsening } \end{array}\right. \end{align*}\]
- State 0 ( $l$ bits are correct) is absorbing.
- $\tau={1, \ldots, l}$:gathered transient class of state.
The transition matrix:
\[P = \begin{pmatrix}I & 0\\ R & Q \end{pmatrix}\]in block form, according to \(E_i = \sum_{j\in T} n_{ij}\) where \(N = (n_{ij}) = (I - Q)^{-1}\).
- $T$: transient states.
- $I$: the unity matrix.
- $Q$: an $(l - 1) \times (l - 1)$ matrix.
- $E_i(t)$: expected time to absorption if started in state $i$.
- Time to absorption: $O(l\cdot \ln l)$.
- Effect of different mutation rate settings:
- $p_m$ is too large: exponential complexity (evolution $\rightarrow$ random search).
- $p_m$ is too small: time to absorption almost constant.
$(1, \lambda)$-GA / $(1 + \lambda)$-GA
Convergence velocity:
\[\begin{align*} \varphi_{(1,/+ \lambda)} &=\sum_{k=k_{\min }}^{l-f_a} k \cdot P_{k^{\prime}=k}(\lambda)\\ &= \sum_{k=k_{\min }}^{l-f_a} k \cdot \sum_{i = 1}^{\lambda}\binom{\lambda}{i} p_{k'=k}^i\cdot p_{k'< k}^{\lambda - i} \end{align*}\]- For $(1 + \lambda)$ and $(1, \lambda)$-GA, we have a single parent $\vec{a}$ and generate $\lambda$ offspring \(O = \{\vec{o}_1, \dots, \vec{o}_{\lambda} \}\).
- ”$,$”: the next generation parent is chosen as the best among offspring, i.e., $\vec{a}_{t + 1} = \text{best}(O_t)$.
- ”$+$”: the next generation parent is chosen as the best among offspring and the old parent, i.e., \(\vec{a}_{t + 1} = \text{best}(O_t\cup \{a_t\})\).
- $(1, \lambda)$-GA: $k_{\min} = -f_a$, $(1 + \lambda)$-GA: $k_{\min} = 0$.
$P_{k’=k}(\lambda)$: the probability of at least one of $\lambda$ offsprings to realize a $k$-step improvement, while the improvement of others is less than $k$. Notice that $(1,/+\lambda)$-GA will only keep the best offspring. Following notations in $(1 + 1)$-GA (Counting Ones), we can express probabilities \(p_{k'=k}, p_{k'>k}, p_{k'< k}\):
\[\begin{align*} p_{k^{\prime}=k} &= \begin{cases}p_a^{+}(k) & , k \geq 0 \\ p_a^{-}(-k) & , k<0\end{cases} \\ p_{k^{\prime}>k} &= \begin{cases}\sum_{i=k+1}^{l-f_a} p_a^{+}(i) & , k \geq 0 \\ \sum_{i=k+1}^{-1} p_a^{-}(-i)+\sum_{i=0}^{l-f_a} p_a^{+}(i) & , k<0\end{cases} \\ p_{k^{\prime}<k} &= 1-p_{k^{\prime}=k}-p_{k^{\prime}>k} \end{align*}\]
$(\mu, \lambda)$-GA / $(\mu + \lambda)$-GA
Convergence velocity:
\[\begin{align*} \varphi_{(\mu,/+\lambda)} &= \frac{1}{\mu}\sum_{k = k_{\min}}^{l - f_a} k\cdot \sum_{\nu = \lambda - \mu + 1}^{\lambda} p_{\nu} (k)\\ &= \frac{1}{\mu}\sum_{k = k_{\min}}^{l - f_a} k\cdot \sum_{\nu = \lambda - \mu + 1}^{\lambda} \sum_{i = 0}^{\nu - 1}\binom{\lambda}{\nu - i - 1}\sum_{j = 0}^{\lambda - \nu}\binom{\lambda - (\nu - 1 - i)}{\lambda - \nu - j} p_{k'=k}^{i + j + 1}\cdot p_{k' < k}^{\nu - i - 1}\cdot p_{k' > k}^{\lambda - \nu - j} \end{align*}\]- $\mu$ parents and $\lambda$ offspring.
- $p_\nu(k)$: the probability of the offspring of rank $\nu$ to improve the objective function value by $k$.
- The rank is the position that the individual is situated when we order all solutions by fitness value (allow ties):
- Individuals: \(\vec{a}_1, \vec{a}_2, \dots, \vec{a}_i, \dots, \vec{a}_{v}, \dots, \vec{a}_j, \dots, \vec{a}_{\lambda}\).
- Fitness values: \(f(\vec{a}_1) \leq f(\vec{a}_2) \leq \dots \leq f(\vec{a}_i) = \dots = f(\vec{a}_\nu) = \dots = f(\vec{a}_j) \leq \dots \leq f(\vec{a}_\lambda)\).
- $\nu - i - 1$ realizations smaller than $k$ ($i = 0, 1, \dots, \nu - 1$).
- $\lambda - \nu - j$ realizations larger than $k$ ($j = 0, 1, \dots, \lambda - \nu)$.
- $i + j + 1$ realizations equals $k$.
Evolution Strategies
Overview
\begin{algorithm}
\caption{Evolution Strategy}
\begin{algorithmic}
\STATE $t \leftarrow 0$
\STATE \texttt{Initialization}$(P(t))$
\STATE \texttt{Evaluation}$(P(t))$
\WHILE{Termination criteria not met}
\STATE $P(t)_{\text{temp}} \leftarrow$ \texttt{Recombination}$(P(t))$
\STATE $P(t)_{\text{temp}} \leftarrow$ \texttt{Mutation}$(P(t)_{\text{temp}})$
\STATE $P(t)_{\text{temp}} \leftarrow$ \texttt{Selection}$(P(t)_{\text{temp}} \cup Q)$
\COMMENT{$Q\in \{\emptyset, P(t)\}$}
\STATE \texttt{Evaluation}$(P(t))$
\STATE $P(t + 1) \leftarrow P_{\text{temp}}(t)$
\STATE $t \leftarrow t + 1$
\ENDWHILE
\end{algorithmic}
\end{algorithm}
Main features
- Mostly real-valued search space $\mathbb{R}^n$. Also mixed-integer, discrete spaces.
- Emphasis on mutation: expectation zero.
- $\lambda \gg\mu $, creation of offspring surplus.
- Self-adaptation of strategy parameters.
- Recombination is applied to all individuals.
- Mutation: normally $n$-dimensional distributed variations, applied to all individuals.
- Selection: $(\mu + \lambda)$-selection (only accept improvements) or $(\mu, \lambda)$-selection (deterioration possible).
Representation
Simple ES with $1/5$ success rule: exogenous adaptation of step size $s$.
\[\mathbf{a} = (x_1, \dots, x_n)\]Self-adaptive ES with single step size: one step-size $\sigma$ controls mutation of all search variables.
\[\mathbf{a} = ((x_1, \dots, x_n), \sigma)\]Self-adaptive ES with individual step sizes: one individual $\sigma_i$ per $x_i$.
\[\mathbf{a} = ((x_1, \dots, x_n), (\sigma_1, \dots, \sigma_n))\]Self-adaptive ES with correlated mutation:
- Individual step size $\sigma_i$.
- One correlation angle per coordinate pair.
- Mutation according to a multivariate Gaussian $\mathcal{N}(0, C)$.
The number of parameters
| Method | $n_{\sigma}$ | $n_{\alpha}$ |
|---|---|---|
| Standard mutation + one global step size | 1 | 0 |
| Standard mutation + individual step sizes | $n$ | 0 |
| Correlated mutations | $n$ | $n(n - 1)/2$ |
| General case (correlated mutations) | $1 \leq n_{\sigma} \leq n$ | $\left(n - \frac{n_{\sigma}}{2}\right)(n_{\sigma} - 1)$ |
Recombination
Overview
\begin{algorithm}
\caption{ES: Recombination}
\begin{algorithmic}
\FOR{$i = 1, \dots, \lambda$}
\STATE Choose recombinant $r_1$ uniformly at random from parent population.
\STATE Choose recombinant $r_2 <> r_1$ uniformly at random from parent population.
\STATE Offspring $\leftarrow$ \texttt{RecombinationOperator}($r_1$, $r_2$)
\STATE Add offspring to offspring population.
\ENDFOR
\end{algorithmic}
\end{algorithm}
Remarks
- Only for $\mu > 1$.
- Directly after selection.
- Iteratively generates $\lambda$ offspring.
Operators
Discrete recombination
- Local: variable at position $i$ will be copied at random (uniformly distributed) from Parent 1 or Parent 2 (at position $i$).
- Global: consider all parents, randomly copied from Parent $k$, $k = 1, \dots, \mu$.
Intermediate recombination
Local: variable at position $i$ is arithmetic mean of Parent 1 and Parent 2 (at position $i$).
\[x_{\text{offspring}, i} = \frac{x_{r_1, i} + x_{r_2, i}}{2}\]Global: consider all parents, arithmetic mean of Parent $k$, $k = 1, \dots, \mu$.
\[x_{\text{offspring}, i} = \frac{1}{\mu} \sum_{k = 1}^{\mu} x_{r_k, i}\]
Mutation
Normal distribution
- Mutation makes use of normally distributed variations.
Probability density function:
\[p(x) = \frac{1}{\sigma \sqrt{2 \pi}} e^{-\frac{(x - \mu)^2}{2 \sigma^2}}\]- Expectation typically zero, $\mu = 0$.
- Standard deviation $\sigma$ needs to be adapted.
Why is a normal distribution used in ES for continuous problems?
- Because it can maximize the unbiasedness.
- Because of its infinite support.
- Because the total probabilities of increasing and decreasing a decision variable are the same.
Idea behind mutation
- Biological model: repair enzymes, mutator genes.
- No deterministic control: strategy parameters evolve.
- Indirect link between fitness and useful strategy parameter settings.
- Hyperparameters $\sigma, \alpha$ are conceivable as an internal model of the local topology.
One $\sigma$ Mutation
- Self-adaptive ES with one step size:
- One $\sigma > 0$ controls mutation for all $x_i$.
- Mutate each search variable with a Gaussian perturbation:
Input: individual before mutation.
\[\mathbf{a} = ((x_1, \dots, x_n), \sigma)\]Mutate the step size.
\[\begin{align*} \sigma' &= \sigma\exp(\tau_0 \cdot g)\\ g &\sim \mathcal{N}(0, 1) \end{align*}\]Mutate search variables.
\[\begin{align*} x_i' &= x_i + \sigma' \cdot \varepsilon_{1, i},\quad \forall i\in\{1, \dots, n\}\\ \varepsilon_{1, i} &\sim \mathcal{N}(0, 1) \end{align*}\]Output: individual after mutation.
\[\mathbf{a'} = ((x_1', \dots, x_n'), \sigma')\]
- $\tau_0$: learning rate.
- Affect the speed of the $\sigma$ adaptation.
- Bigger $\tau_0$: faster but less precise.
- Smaller $\tau_0$: slower but more precise.
Recommended value by Schwefel:
\[\tau_0 = \frac{1}{\sqrt{n}}\]
- Affect the speed of the $\sigma$ adaptation.
The length of the mutation vector:
\[\begin{align*} \Vert \vec{x} - \vec{x}\Vert_2 &= \sqrt{\sum_{i = 1}^n(x'_i - x_i)^2}\\ &= \sqrt{\sum_{i = 1}^n \sigma'^2Z_i^2}\\ &= \sigma'\sqrt{\sum_{i = 1}^n Z_i^2}\\ &= \sigma' \gamma \end{align*}\]$Z_i\sim \mathcal{N}(0, 1) \Rightarrow \sum_{i = 1}^n Z_i^2\sim \chi^2(n) \Rightarrow \gamma = \sqrt{\sum_{i = 1}^n Z_i^2}\sim \chi(n)$.
\[\begin{align*} E[\Vert \vec{x}' - \vec{x} \Vert_2] &= E[\sigma'\gamma]\\ &= \sigma'E[\gamma]\\ Var[\Vert \vec{x}' - \vec{x} \Vert_2] &= Var[\sigma'\gamma]\\ &= \sigma'^2 Var[\gamma] \end{align*}\]$\chi^2(n)$ distribution
- Mean: $n$.
- Variance: $2n$.
$\chi(n)$ distribution
Mean:
\[\mu = \frac{\sqrt{2} \Gamma\left(\frac{1}{2}(n + 1)\right)}{\Gamma\left(\frac{1}{2}n\right)}\]Variance:
\[\sigma^2 = \frac{2\left[\Gamma\left(\frac{1}{2}n\right) \Gamma\left(1 + \frac{1}{2}n\right) - \Gamma^2\left(\frac{1}{2}(n + 1)\right)\right]}{\Gamma^2\left(\frac{1}{2}n\right)}\]$\Gamma$ function:
- $\Gamma(z) = \int_{0}^\infty t^{z - 1}e^{-t}dt$.
- $\Gamma(z + 1) = z\Gamma(z)$.
- $\Gamma(1) = 1, \Gamma\left(\frac{1}{2}\right) = \sqrt{\pi}$.
- The mutation procedure is un-bias and isotropic.
- Advantages.
- Simple adaptation mechanism.
- Self-adaptation usually fast and precise.
- Disadvantages.
- Bad adaptation in case of complicated contour lines.
- Bad adaptation in case of very differently scaled object variables.
Individual $\sigma_i$ Mutation
- Self-adaptive ES with individual step sizes: one $\sigma_i$ per $x_i$.
Input: individual before mutation.
\[\mathbf{a} = ((x_1, \dots, x_n), (\sigma_1, \dots, \sigma_n))\]Sample a global perturbation.
\[g\sim \mathcal{N}(0, 1)\]Mutate individual step sizes.
\[\begin{align*} \sigma'_i &= \sigma_i\exp(\tau'g + \tau \varepsilon_{1, i}),\quad i\in\{1,\dots, n\} \\ \varepsilon_{1, i}&\sim\mathcal{N}(0, 1) \end{align*}\]Mutate search variables.
\[\begin{align*} x_i' &= x_i + \sigma_i'\cdot \varepsilon_{2, i},\quad i\in\{1, \dots, n\}\\ \varepsilon_{2, i}&\sim\mathcal{N}(0, 1) \end{align*}\]Output: individual after mutation.
\[\mathbf{a}' = ((x_1', \dots, x_n'), (\sigma_1', \dots, \sigma_n'))\]
- $\tau, \tau’$ are learning rates.
- $\tau’$: global learning rate. \(\mathcal{N}(0, \tau'^2)\) has only one realization.
- $\tau$: local learning rate. \(\mathcal{N}(0, \tau^2)\) has $n$ realizations.
Recommended values by Schwefel:
\[\tau' = \frac{1}{\sqrt{2n}},\quad \tau = \frac{1}{\sqrt{2\sqrt{n}}}\]
The mutation vector elements are defined as:
\[\begin{align*} x'_i - x_i &= \sigma'_iZ_i\\ \frac{x'_i - x_i}{\sigma'} &= Z_i\\ \sum_{i = 1}^n \frac{(x'_i - x_i)^2}{(\sigma'_2)^2} &= \sum_{i = 1}^n (Z_i)^2\\ E\left[\sum_{i = 1}^n \frac{(x'_i - x_i)^2}{(\sigma'_2)^2}\right] &= n \end{align*}\]The new solutions after mutation are located on an ellipsoid around the initial point. In 2 dimensions, we have:
\[\frac{(x'_1 - x_1)^2}{(\sigma'_1)^2} + \frac{(x'_2 - x_2)^2}{(\sigma'_2)^2} = 2\]
- Advantages.
- Individual scaling of object variables.
- Increased global convergence reliability.
- Disadvantages.
- Slower convergence due to increased learning effort.
- No rotation of coordinate system possible, which is required for badly conditioned objective function.
Correlated Mutations
- Self-adaptive ES with correlated mutations:
- Individual step sizes.
- One rotation angle for each pair of coordinates.
Mutation according to covariance matrix $\mathcal{N}(0, C)$.
Input: individual before mutation.
\[\mathbf{a} = ((x_1, \dots, x_n), (\sigma_1, \dots, \sigma_n), (\alpha_1, \dots, \alpha_{n(n - 1)/2}))\]Mutation of individual step sizes.
\[\begin{align*} \sigma'_i &= \sigma \cdot\exp(\tau'g + \tau\varepsilon_{1, i}),\quad i\in\{1, \dots, n\}\\ g&\sim \mathcal{N}(0, 1)\\ \varepsilon_{1, i}&\sim \mathcal{N}(0, 1) \end{align*}\]Mutation of rotation angles.
\[\begin{align*} \alpha'_i &= \alpha_i + \beta\varepsilon_{2, i}\\ \varepsilon_{2, i} &\sim \mathcal{N}(0, 1) \end{align*}\]Mutation of decision variables.
\[x'_i = x_i + \mathcal{N}(0, C')\]Output: individual after mutation.
\[\mathbf{a}' = ((x'_1, \dots, x'_n), (\sigma'_1, \dots, \sigma'_n), (\alpha'_1, \dots, \alpha'_{n(n - 1)/2}))\]
- How to create $\mathcal{N}(0, C’)$?
Multiplication of uncorrelated mutation vector with $n(n - 1) / 2$ rotational matrices.
\[\begin{align*} \mathbf{C}^{\frac{1}{2}} & =\left(\prod_{i=1}^{n-1} \prod_{j=i+1}^n R\left(\alpha_{i j}\right)\right)\left[\begin{array}{lll} \sigma_1 & & \\ & \ddots & \\ & & \sigma_n \end{array}\right] \\ \mathbf{C} & =\mathbf{C}^{\frac{1}{2}} \mathbf{C}^{\frac{1}{2}} \end{align*}\]Structure of rotation matrix.
\[R(\alpha_{ij}) = \begin{pmatrix} 1 & & & & & & & 0\\ & 1 & & & & & 0 & \\ & &\cos(\alpha_{ij}) & & & -\sin(\alpha_{ij}) & & \\ & & & 1 & & & & \\ & & & & 1 & & & \\ & &\sin(\alpha_{ij}) & & & \cos(\alpha_{ij}) & & \\ & 0 & & & & & 1 & \\ 0 & & & & & & & 1\\ \end{pmatrix}\]$C$ is the covariance matrix: $C = \text{Cov}(X, X) = E[(X - E[X])(X - E[X])^T]$.
\[f_X(\mathbf{x}) = \frac{1}{(2\pi)^{\frac{n}{2}}\vert C\vert^{\frac{1}{2}}}\exp\left( -\frac{1}{2}(\mathbf{x} - \mathbf{\mu})^TC^{-1}(\mathbf{x} - \mathbf{\mu}) \right)\]
- $\tau, \tau’, \beta$ are learning rates.
- $\tau, \tau’$ are as before.
- $\beta = \frac{\pi}{36}\approx 0.0873$, corresponding to 5 degrees.
Out of boundary correction:
\[\vert \alpha'_j\vert > \pi \Rightarrow \alpha'_j \leftarrow \alpha'_j - 2\pi \cdot \text{sign}(\alpha'_j)\]
- Advantages.
- Individual scaling of object variables.
- Rotation of coordinate system possible.
- Increased global convergence reliability.
- Disavantages.
- Much slower convergence.
- Effort for mutations scales quadratically.
- Self-adaptation very inefficient.
Selection
Operators
$(\mu + \lambda)$ Selection
- $\mu$ parents produce $\lambda$ pffspring by recombination (optional) and mutation (necessary).
- $\mu + \lambda$ individuals will be considered together.
- Deterministic selection: the $\mu$ best out of $\mu + \lambda$ will be selected.
- This method guarantees monotonicity: deteriorations will never be accepted.
Both $\mu > \lambda$ and $\frac{\mu}{\lambda} = 1$ are reasonable.
$(\mu , \lambda)$ Selection
- $\mu$ parents produce $\lambda \gg \mu$ pffspring by recombination (optional) and mutation (necessary).
- $\lambda$ offspring will be considered alone.
- Deterministic selection: the $\mu$ best out of $\lambda$ offspring will be selected.
- This method doesn’t guarantee monotonicity.
- Deteriorations are possible.
- The best objective function value in generation $t + 1$ may be worse than the best in generation $t$.
Selective Pressure
Measure the selective pressure: takeover time $\tau^*$.
- The number of generations until repeated application of selection completely fills the population with copies of the initially best individual.
Example 1: $(\mu, \lambda)$ selection. $\tau^* = \frac{\ln\lambda}{\ln\lambda/\mu}$.
Proof
Suppose that we run an ES with $(\mu, \lambda)$ selection without crossover and mutation. Let $x^*$ be the best solution in generation $t = 0$. At time $t = 0$ there is one instance of $x^∗$ in the population (denoted by $N_0 = 1$). We can derive the general expression for $N_t$
Calculate the take overtime:
\[\begin{align*} \lambda &= \left(\frac{\lambda}{\mu}\right)^t\\ t & =\log _{\frac{\lambda}{\mu}} \lambda \\ & =\frac{\log \lambda}{\log \frac{\lambda}{\mu}} \\ & =\frac{\ln \lambda}{\ln \frac{\lambda}{\mu}} \end{align*}\]Example 2: Proportional selection in genetic algorithms. $\tau^* \approx \lambda\ln\lambda$.
Self-adaptation
Concepts
- No deterministic step size control. Rather: evolution of step sizes.
- Intuitions.
- Indirect coupling: step sizes – progress.
- Good step sizes improve individuals. Bad ones make them worse. This yields an indirect step size selection.
- Without exogeneous control.
- By recombining / mutating the strategy parameters.
- By exploiting the implicit link between fitness and useful internal models.
Conditions
- Found by experiments.
- Generation of an offspring surplus, $\lambda > \mu$.
- $(\mu, \lambda)$ selection to guarantee extinction of misadapted individuals.
- A not too strong selective pressure, e.g., $(15,100)$ where $\lambda/\mu \approx 7$.
- Certainly, $\mu > 1$ necessary.
- Recombination also on strategy parameters (especially: intermediary recombination).
Empirical Test Design
- Simple functions with predictable optimal $\sigma_i$ values. Check whether it works.
- Compare with optimal behavior (if known).
- Investigate impact of selection.
Sphere model
Test function: one common step size, $n_\sigma = 1$:
\[f(\mathbf{x}) = \sum_{i = 1}^n x_i^2\]- $(1, 10)$-ES vs $(1 + 10)$-ES: the “non-greedy” $(1,10)$-ES performs better.
- Progress: $P_g = \log\sqrt{\frac{f_{\min}(0)}{f_{\min}(g)}}$.
- Counterintuitive: elitist is a bad choice.
- Misadapted $\sigma$ might survive in an elitist strategy.
- Forgetting is necessary to prevent stagnation periods.
- Test: need to know optimal step size. Only for very simple, convex objective functions.
- Dynamic sphere model: optimum locations changes occasionally.
- Summary of self-adaptation of one step size.
- Perfect adaptation.
- Learning time for back adaptation proportional $n$.
- Proofs only for convex functions.
Individual step sizes
Test function: appropriate scaling of variables, $n_\sigma = n$. Ellipsoid model:
\[f(\mathbf{x}) = \sum_{i = 1}^n ix_i^2\]Collective learning.
- Individuals exchange information about their “internal models” by recombination.
- A $(\mu, 100)$-ES with \(\mu\in\{1, \dots, 30\}\).
- $n_\sigma = n = 30$ and the optimal $\sigma_i\propto 1/\sqrt{i}$ is known for ellipsoid model.
- Optimum setting of $\sigma_i$: $\mu = 1$ is best.
Covariances
Test function: a metric, \(n_{\sigma} = n, n_\alpha = n(n - 1) / 2\).
\[f(\mathbf{x}) = \sum_{i = 1}^n\left( \sum_{j = 1}^i x_j \right)^2\]- Recombination.
- Intermediary on $x_i$.
- Global intermediary on $\sigma_i$.
- None on $\alpha_i$ (covariances).
- Covariances increase effectiveness in case of rotated coordinate systems.
Convergence Velocity: $(1 + 1)$-ES
Definition of convergence velocity: expectation of the distance towards the optimum covered per generation.
\[\begin{align*} \varphi &= E[\Vert \mathbf{x}^* - \mathbf{x}_t\Vert - \Vert \mathbf{x}^* - \mathbf{x}_{t + 1}\Vert]\\ &= E[\vert f(\mathbf{x}^*) - f(\mathbf{x}_t) \vert - \vert f(\mathbf{x}^*) - f(\mathbf{x}_{t + 1}) \vert] \end{align*}\]Linear model. Assume $Z’_1\sim \mathcal{N}(0, \sigma^2), Z_1\sim \mathcal{N}(0, 1)$.
\[\begin{align*} \varphi &= E[Z'_1]\\ &= \sigma E[Z_1]\\ &= \sigma \int_{0}^{\infty} z_1 \phi(z_1)dz_1\\ &= \frac{\sigma}{\sqrt{2\pi}} \int_{0}^{\infty} z_1 \exp\left(-\frac{z_1^2}{2}\right) dz_1\\ &= \frac{\sigma}{\sqrt{2\pi}} \end{align*}\]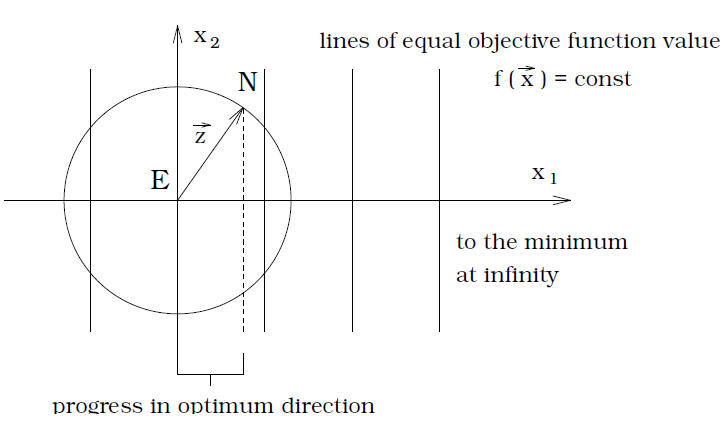
- Success probability: $1/2$.
Corridor model: $f(\mathbf{x}) = c\cdot x_1,\quad -b \leq x_2, \dots, x_n\leq b$.

- Results.
Convergence velocity.
\[\varphi = \frac{\sigma}{\sqrt{2\pi}} \left(1 - \frac{\sigma}{b\sqrt{2\pi}} \right)^{n - 1}\]Normalized convergence velocity, $\varphi’ = \frac{\varphi n}{b}, \sigma’ = \frac{\sigma n}{b}$.
\[\varphi'\approx \frac{\sigma'}{\sqrt{2\pi}}\exp\left(-\frac{\sigma'}{\sqrt{2\pi}} \right),\quad \text{for } n\gg 1\]Success probability.
\[\omega_e\approx \frac{1}{2}\exp\left(-\frac{\sigma'}{\sqrt{2\pi}} \right),\quad \text{for }n\gg 1\]
- Corollaries.
- Optimal standard deviation: $\sigma’_{\text{opt}} = \sqrt{2\pi}$.
- Maximum convergence velocity: $\varphi’_{\max} = \frac{1}{e}$.
- Optimal success probability: $\omega_{\text{opt}} = \frac{1}{2e}\approx 0.1839$.
- Results.
Sphere model: \(f(\mathbf{x}) = \sum_{i = 1}^n x_i^2 = r^2\).
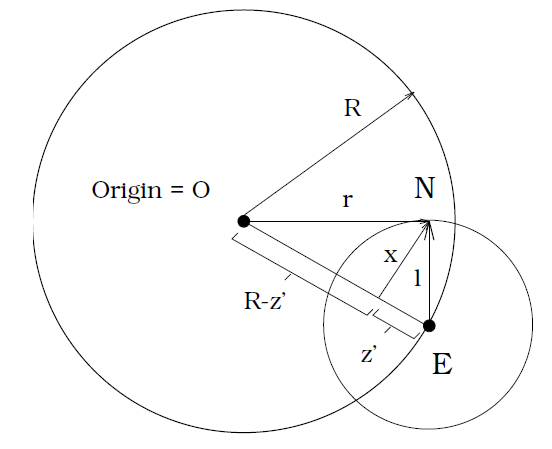
By geometry:
\[\begin{align*} z'^2 + x^2 &= l^2\\ &= x^2 + (R - z')^2\\ &= r^2\\ &= l^2 + R^2 - 2Rz' \end{align*}\]- Note that the offspring originates in the perimeter of the parent’s circle.
- The resulting offspring’s mutations are considered degenerative if they are outside the parent’s circumference. That is only the part of the offspring’s circle that is within the parent’s circle is “good”.
- Thus, the lower bound of good improvements is when the mutation falls on the intersection between the circles.
- Results.
Convergence velocity.
\[\begin{align*} \varphi & =E\left(R^2-r^2\right)=E\left(2 R Z^{\prime}-l^2\right) \\ & =E\left(2 R \sigma Z-\sigma^2 n\right) \\ & =\cdots \\ & =2 R \sigma \int_{z_{\min }}^{\infty} z \phi(z) d z-\sigma^2 n \int_{z_{\min }}^{\infty} \phi(z) d z \\ & =\frac{2 R \sigma}{\sqrt{2 \pi}} \exp \left(-\frac{\sigma^2 n^2}{8 R^2}\right)-\sigma^2 n\left(1-\Phi\left(\frac{\sigma n}{2 R}\right)\right) \end{align*}\]Success probability: $\omega: 1 - \Phi(\sigma’/2)$.
- Corollaries.
- Optimal standard deviation: $\sigma’\approx 1.224$.
- Maximum convergence velocity: $\varphi’\approx 0.2025$.
- Optimal success probability: $\omega_{e_{\text{opt}}}\approx 0.270$.
$1/5$ success rule.
\(\omega_{e_{\text{opt}}}\) should be about $1/5$. If $\omega_e$ (measured during execution of the $(1 + 1)$-ES) is larger than $1/5$, increase $\sigma$. If it is smaller than $1/5$, decrease $\sigma$.
\[\sigma(t + n) = \begin{cases} \sigma(t) \cdot k,\quad &\omega_e < 1/5,\\ \sigma(t) / k,\quad &\omega_e \geq 1/5,\\ \end{cases}\]The empirical success $\omega_e$ should be around $1/5$. If it is much higher, it means that the step size $\sigma$ used is too small. Similarly, if it’s lower than $1/5$ the step size $\sigma$ is too large.
- Recommended choice of $k$: $k\approx 0.82$.
- Plot of optimal progress against the success probability $(1 - \Phi(\sigma’/2))$. The small window between the intersections (marked in red) is where we find the optimal step sizes $\sigma$. The empircial success should be around $1/5$, if it is higher or lower it is an indication that the step size is too small / large respectively (in yellow in the graph).
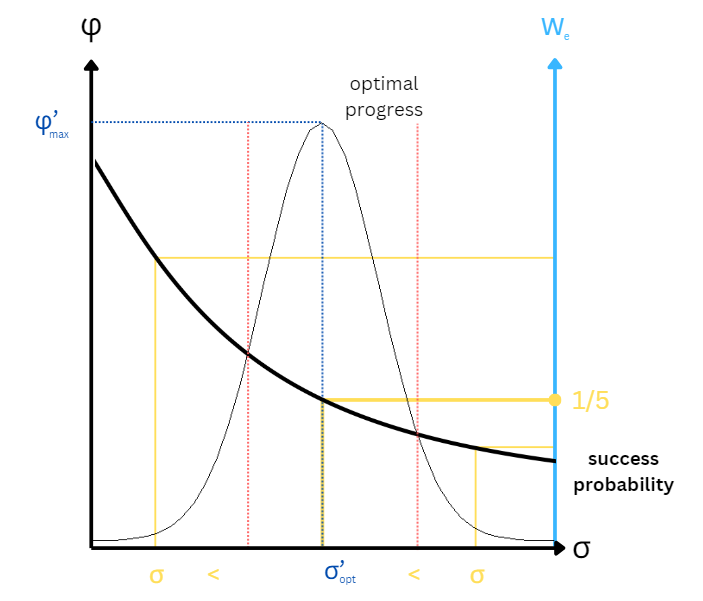
Key points about $1/5$ success rule
- Theoretical success probability / rate is monotonically decreasing with respect to the step-size.
- Theoretical success probability can be easily measured empirically by counting the number of successful mutations over a some period.
- The theoretical progress rate is a unimodal (with a single peak) function of the step-size.
- We can compute the optimal step-size at the peak value of progress rate curve and calculate the optimal success rate that is the success rate at the optimal step-size, which is about $1/5$.
- In practice, we increase the step-size if the measured success rate is larger than the optimal success rate and vice versa, since probability / rate is monotonically decreasing with respect to the step-size.
- Disadvantages of $(1 + 1)$-ES.
- Certainly a more local search method.
- $1/5$ success rule may fail.
Log-normal distribution
- pdf: \(f_X(x) = \frac{1}{\sigma x\sqrt{2\pi}}\exp\left(-\frac{(\ln x - \mu)^2}{2\sigma^2}\right)\)
- $\mu = 0, \sigma = 1$
- Why is a log-normal distribution used to update step size in ES?
- A log-normal distribution can guarantee that the updated step size is a positive number.
- A log-normal distribution can guarantee the same probability to increase and decrease a step size.
Benchmarking and Empirical Analysis
Benchmarking
- A problem class of interest: domain, single-/multi-objective, black/white/grey-box, dimensionality.
- A set of test functions: \(\mathcal{F} = \{f_1, f_2, \dots\}\).
- Universality: the larger, the better.
- Test functions should not be similar: explorative landscape analysis.
- A set of optimization algorithms: \(\mathcal{A} = \{A_1, A_2, \dots\}\).
- Performance measure / indicators.
Speed: running time / the number of function evaluations (integer-valued random variables).
\[T(A, f, d, v) \in [1,\dots, B]\cup \{\infty\}\]Quality: function values (real-valued variables).
\[V(A, f, d, v)\in\mathbb{R}\]Interested in the distribution of $T$ and $V$.
- Execution: run each pair of $(A, f, d)$ for several times independently.
Estimate the empirical distribution.
\[\begin{align*} \{v_1, v_2, \dots, v_r\} \rightarrow \hat{F}_V\\ \{t_1, t_2, \dots, t_r\} \rightarrow \hat{F}_T\\ \end{align*}\]- Stopping criteria: a budget on the function evaluation, a target function value to hit, etc.
- The behavior of the optimization algorithm is usually stochastic.
- Use enough data / evidence to determine the number of runs / repetitions $r$.
Performance Analysis
Empirical behavior
- Trajectory in the search space.
- Evolution of objective values.
Performance Measure
Stochastic behavior $\rightarrow$ statistical characteristics.
Convergence rate
\[\begin{align*} &\lim_{n\rightarrow \infty} \frac{\Delta f_n}{T_n}\\ =&\lim_{n\rightarrow \infty} \frac{\vert f_{n}^{\text{best}} - f^* \vert}{\sum_{i = 1}^n\#\text{EVAL}_i}\\ \end{align*}\]- Asymptotic behavior.
- Not very practical.
- Requires lots of runs.
- Not always linear.
- Not always constant.
Empirical performance
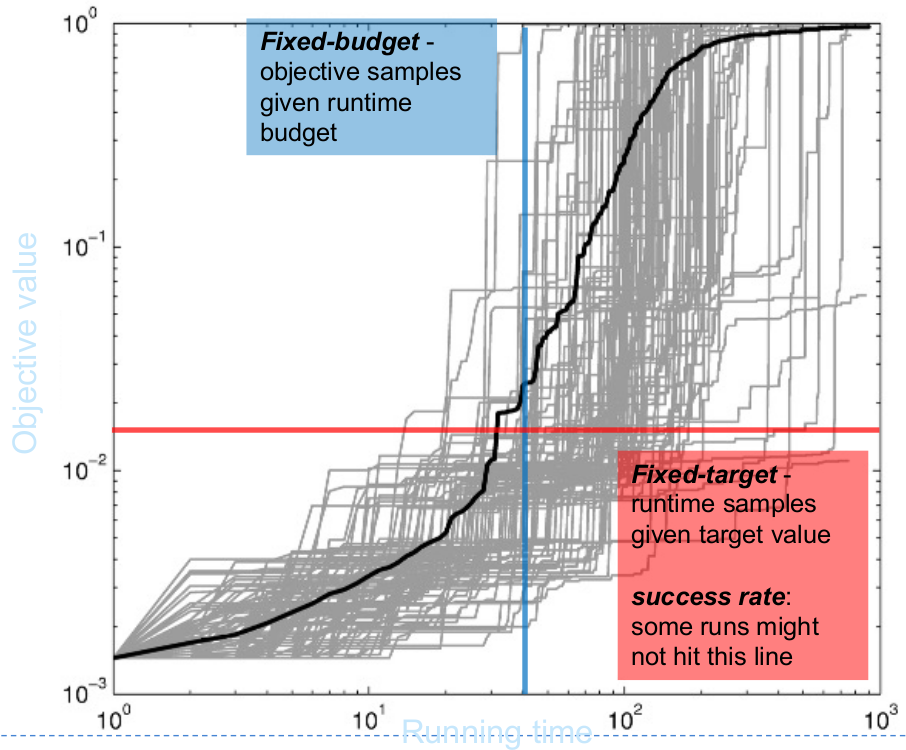
- Measure cost: fixed-target running time.
- Horizontal perspective.
- Recommended in the benchmarking.
Advantage due to quantitative comparison.
\[\begin{align*} T(f_{\text{target}}) &\in \mathbb{N}_{>0} \Rightarrow \{t_1(f_{\text{target}}), \dots, t_r(f_{\text{target}})\}\\ N_{\text{success}} &= \sum_{i = 1}^r \mathbf{1}(t_i(f_{\text{target}}) < \infty) \end{align*}\]
- Measure quality: fixed-budget objective value.
- Vertical perspective.
- Only for qualitative comparison.
Directly applicable for runs with very small number of function evaluations.
\[V(b) \in \mathbb{R}, b<B \Rightarrow \{v_1(b), \dots, v_r(b)\}\]
Descriptive statistics
Sample mean: underestimates the mean of running times when infinite budget is allowed.
\[\begin{align*} \bar{T}(v) &= \frac{1}{r}\min\{t_i(A, f, d, v), B\},\\ \bar{V}(v) &= \frac{1}{r}\sum_{i = 1}^rv_i(A, f, d, t) \end{align*}\]Sample quantiles.
\[\frac{\{t_i\leq Q_{m\%} \}}{r} = m\%\]Empirical success rate.
\[\widehat{p}_s=\sum_{i=1}^r \mathbb{1}\left(t_i(A, f, d, v)<\infty\right) / r \stackrel{P}{\longrightarrow} \mathrm{E}[\mathbb{1}(T(A, f, d, v)<\infty)]\]
Expected running time (ERT)
Unbiased estimator the mean running time.
Example
- Algorithm A: 40 runs, 2000 evaluations on average, 75% success rate.
- Algorithm B: 40 runs, 3000 evaluations on average, 90% success rate.
- ERT.
- Algorithm A: $\frac{2000}{0.75} \approx 2666.7$.
- Algorithm B: $\frac{3000}{0.9} \approx 3333.3$.
Empirical cumulative distribution functions (ECDFs)
Taking the running time for example.
\[\widehat{F}_T(t ; A, f, d, v)=\frac{\text { the number of running time values } \leq t}{r}=\frac{1}{r} \sum_{i=1}^r \mathbb{1}\left(t_i(A, f, d, v) \leq t\right) \text {. }\]ECDF converges to the “true” distribution function.
\[\sqrt{r}\left(\widehat{F}_T(t)-F_T(t)\right) \stackrel{d}{\longrightarrow} \mathcal{N}\left(0, F_T(t)\left(1-F_T(t)\right)\right)\]Aggregate ECDFs.
Over multiple targets.
\[\widehat{F}_T(t ; A, f, d, \mathcal{V})=\frac{1}{r|\mathcal{V}|} \sum_{v \in \mathcal{V}} \sum_{i=1}^r \mathbb{1}\left(t_i(A, f, d, v) \leq t\right)\]Over multiple functions.
\[\widehat{F}_T(t ; A, \mathcal{F}, d, \mathcal{V})=\frac{1}{r|\mathcal{V} \| \mathcal{F}|} \sum_{f \in \mathcal{F}} \sum_{v \in \mathcal{V}} \sum_{i=1}^r \mathbb{1}\left(t_i(A, f, d, v) \leq t\right)\]
References
- Slides of Evolutionary Algorithms course, 2023 Fall, Leiden University.
- Selection (genetic algorithm).
- Geof H. Givens and Jennifer A. Hoeting. Computational Statistics. John Wiley & Sons, Ltd, 2012.
- Tournament Selection (GA).
- Tournament selection.
- Crossover (genetic algorithm).
- Partially Mapped Crossover in Genetic Algorithms.
- Gray code.
- Chi Distribution.
- Gamma function.