LLMs:模型架构 Model Architecture
记录最近学习大模型的进展,主要参考 Stanford CS336。感谢将课程资源开源的教授们!
P.S. 笔记整理使用了 DeepSeek 和 Gemini 作为助理。
深度学习算法
- 经典深度学习网络模型:FFN、CNN、RNN、GNN。
- 优化器:SGD、AdaGrad、RMSProp、Adam、AdamW。
Transformer 以及后续的改进工作
- 2017 年,谷歌在论文 Attention Is All You Need 中提出 Transformer 模型。现在的绝大多数大模型都基于 Transformer 架构或者其变体构建。
- Transformer 模型架构图。左半部分为 Encoder,右半部分为 Decoder。
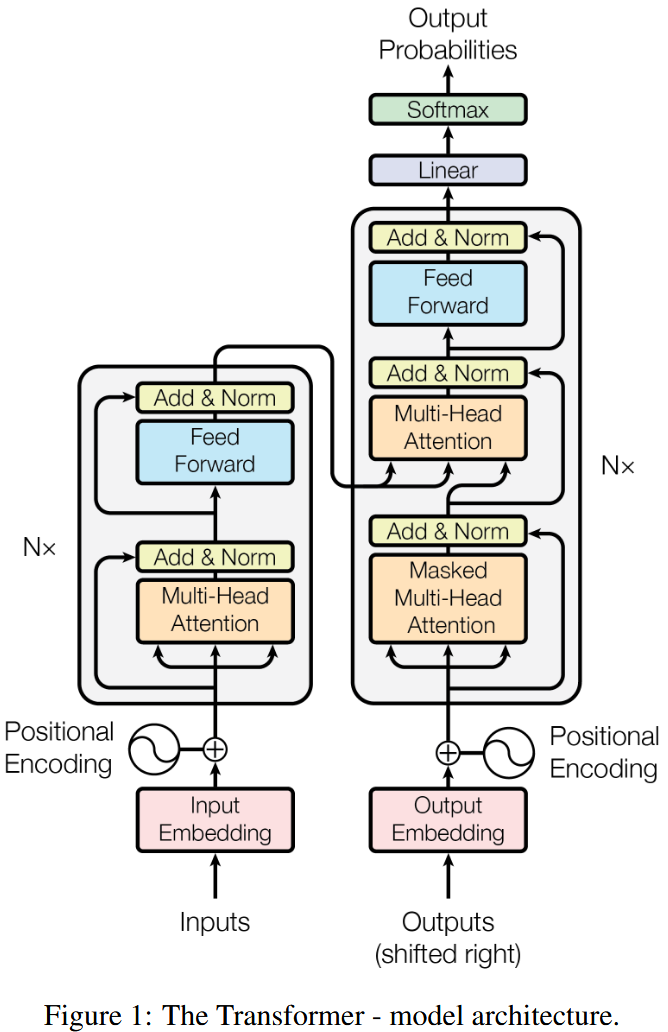
- Transformer 的核心为自注意力机制模块。
- Transformer 的组成元素
- 位置编码
- 多头注意力机制模块
- 残差连接
- FFN 及归一化层
- Softmax 层
- Transformer 后续改进工作的部分内容参考了 Stanford CS336 Lecture 3。
自注意力机制 Self-Attention
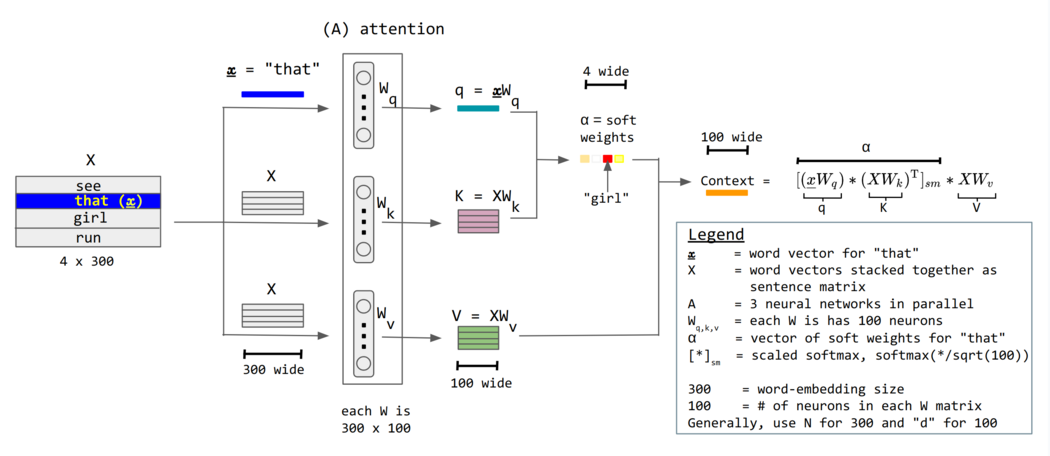
\[\text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V\]
- Self-Attention 步骤拆解
- 编码位置信息:输入 $x$ + 位置编码 $p$ = 带位置编码信息的输入 $z$。
- 计算查询 $Q$(Query)、键 $K$(Key)、值 $V$(Value)矩阵。
- $z$ 经过线性变换得到 $Q$、$K$、$V$。
- 计算注意力权重。
- 根据注意力权重从 $z$ 抽取特征。
- 上述公式做了什么
- $QK^T$:点积,计算查询与键的相似度。
- 除以 $\sqrt{d_k}$:Scaling,缩放操作。
Softmax:将相似度转化为一个概率分布,可以看作值 $V$ 的重要程度(权重)。
- 复杂度:对于序列长度为 $n$,维度为 $d$ 的输入
- 计算复杂度:$O(n² \cdot d)$。
- 空间复杂度:$O(n²)$。
位置编码
Sine 编码
- 模型:原始 Transformer。
通过正弦和余弦函数编码位置信息。
\[\begin{align*} \text{Embed}(x, i) &= v_x + PE_{pos} \\ PE_{(pos, 2i)} &= \sin(pos / 10000^{2i / d_{model}}) \\ PE_{(pos, 2i + 1)} &= \cos(pos / 10000^{2i / d_{model}}) \\ \end{align*}\]
绝对位置编码
- 模型:GPT 1/2/3、OPT。
直接添加一个位置向量到 embedding。
\[\text{Embed}(x, i) = v_x + u_i\]
相对位置编码
- 模型:T5、Gopher、Chinchilla。
添加位置向量到注意力计算。
\[e_{ij} = \frac{x_iW^Q(x_jW^K + a_{ij}^K)^T}{\sqrt{d_z}}\]
ALiBi
- ALiBi:Attention with Linear Biases。
- 模型:MosaicML 的 MPT 系列模型。
无需参数的位置编码方法,通过线性偏置来惩罚注意力机制中的远距离交互。具体而言,ALiBi 在计算注意力分数时,为每个 token 对(token pair)添加一个固定的、基于距离的偏置(bias)。
\[\text{ALiBi Attention Score} = \text{Softmax}(QKᵀ - m \cdot |i - j|) V\]- $i$ 和 $j$:分别是查询(Query)和键(Key)所在的位置索引。
- $\vert i - j\vert$:两个 token 之间的距离。
- $-\vert i - j\vert$:距离越远,这个负数的绝对值就越大(即值越小)。这意味着距离越远的 Key,会受到一个越大的惩罚。
- $m$:斜率,是一个根据注意力头(head)预先定义好的、递减的几何序列。例如,8 个头对应的 $m$ 可能是 $[1/2, 1/4, 1/8, …, 1/256]$。
RoPE
- RoPE:Rotary Position Embedding。
- 模型:GPTJ、PaLM、LLaMA、2024 年及之后推出的大多数 LLM。
- 核心思想:一个好的相对位置编码方案,应该确保任意两个 token 之间的注意力分数(通常通过点积计算)只依赖于它们之间的相对位置,而与它们的绝对位置无关。
数学表达如下
\[\langle f(x,i),f(y,i)\rangle = g(x, y, i − j)\]- $x$ 和 $y$ 代表两个输入 token。
- $i$ 和 $j$ 代表它们在序列中的绝对位置。
- $f(x,i)$ 是将 token $x$ 及其位置 $i$ 编码后的向量。
- $\langle f(x,i),f(y,i)\rangle$ 代表这两个编码向量的点积运算。
- $g(x, y, i − j)$ 是一个函数,它只取决于 token $x$、token $y$ 的内容,以及它们之间的相对距离 $i−j$。
现有位置编码方法的不足
Sine 编码:计算位置嵌入的点积会产生包含绝对位置交叉项的复杂项。
\[\begin{align*} &\langle \text{Embed}(x, i), \text{Embed}(y, j) \rangle \\ =& \langle v_x, v_y \rangle + \langle PE_i, v_y \rangle + \langle v_x, PE_j \rangle + \langle PE_i, PE_j \rangle \end{align*}\]重点看最后一项。它的展开式中会出现如下形式的项(利用三角函数公式 $\cos(A)\sin(B) = \frac{1}{2}(\sin(A+B) − \sin(A−B))$ 等):
\[\begin{align*} &\sum_k \sin \left( \frac{i}{10000^{k/d_{\text{model}}}} \right) \cos \left( \frac{j}{10000^{k / d_{\text{model}}}} \right)\\ =& \frac{1}{2} \sum_k \left[ \sin \left( \frac{i + j}{10000^{k / d_{\text{model}}}} \right) + \sin \left( \frac{i - j}{10000^{k / d_{\text{model}}}} \right) \right] \end{align*}\]这个公式展示了问题所在:
- $\sin (\dots (i−j) \dots)$ 项:这部分是相对位置信息,需要保留。
- $\sin(\dots (i + j) \dots)$ 项:这部分是交叉项,它的值同时依赖于两个 token 的绝对位置之和 $i+j$。
- 绝对位置编码:直接依赖于绝对位置。
- 相对位置编码:通过复杂矩阵计算引入相对位置信息,而不是简单的内积。
- 方法:通过旋转矩阵(Rotation Matrix)对查询(Query)和键(Key)向量进行旋转,旋转的角度取决于它们各自的绝对位置。这样,两个向量在点积(计算注意力分数)时,其结果会自动携带上它们之间的相对位置信息。
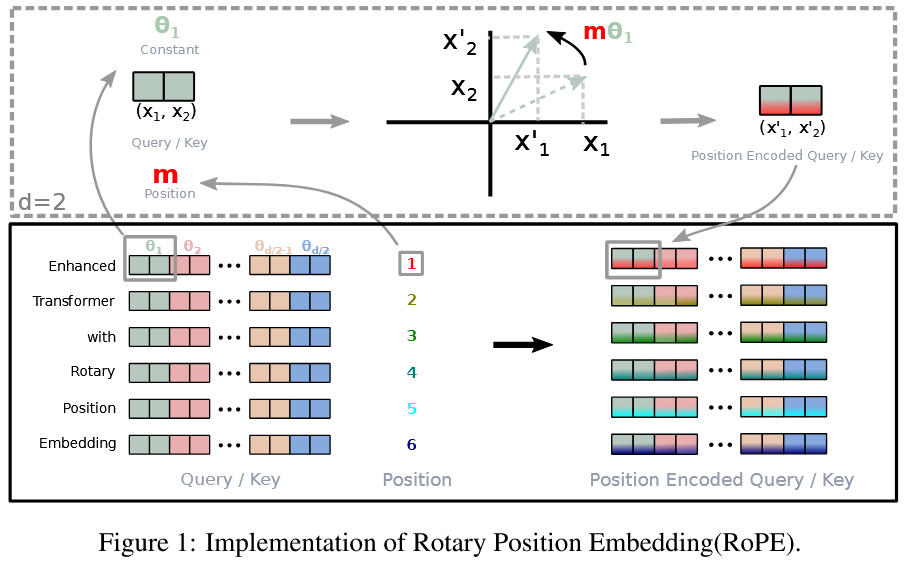
图片来源:RoFormer: Enhanced Transformer with Rotary Position Embedding
- 步骤
- 对于序列中位置为 $m$ 的 token,我们想将其查询向量 $\mathbf{q}_m$ 和键向量 $\mathbf{k}_n$ 转换为融入了位置 $m$ 和 $n$ 的 $\tilde{\mathbf{q}}_m$ 和 $\tilde{\mathbf{k}}_n$。
- RoPE 通过一个复数的视角,使用旋转矩阵来操作。对于向量的每一对维度(例如第 $i$ 和 $i+1$ 维),将其视为一个复数,然后进行旋转。
旋转矩阵 $R_{\Theta, m}$ 定义为:
\[R_{\Theta, m} = \begin{pmatrix} \cos m\theta_i & -\sin m\theta_i \\ \sin m\theta_i & \cos m\theta_i \end{pmatrix}\]其中:
- $m$ 是绝对位置。
- $\theta_i$ 是预设的频率值,通常设置为 $\theta_i = 10000^{-2i/d}$,$d$ 是向量总维度。这个频率决定了旋转的速度,不同维度有不同的旋转速度。
应用旋转
对于查询向量 \(\mathbf{q}_m\),我们将其每一组二维分量 \((q_m^{(i)}, q_m^{(i+1)})\) 与旋转矩阵 \(R_{\Theta, m}\) 相乘:
\[\tilde{\mathbf{q}}_m = R_{\Theta, m} \mathbf{q}_m\]同样地,对于键向量 $\mathbf{k}_n$:
\[\tilde{\mathbf{k}}_n = R_{\Theta, n} \mathbf{k}_n\]
- 计算注意力分数
计算融入了位置信息的查询和键的点积,即注意力分数:
\[\langle R_{\Theta, m} \mathbf{q}_m, R_{\Theta, n} \mathbf{k}_n \rangle\]根据旋转矩阵的性质和三角恒等式,可以推导出:
\[\langle R_{\Theta, m} \mathbf{q}_m, R_{\Theta, n} \mathbf{k}_n \rangle = \langle \mathbf{q}_m, R_{\Theta, n-m} \mathbf{k}_n \rangle\]上述式子说明旋转后的 $\mathbf{q}_m$ 和 $\mathbf{k}_n$ 的点积,只依赖于原始的 $\mathbf{q}_m$、$\mathbf{k}_n$ 和它们的相对位置 $(m-n)$。
Post-LN vs Pre-LN
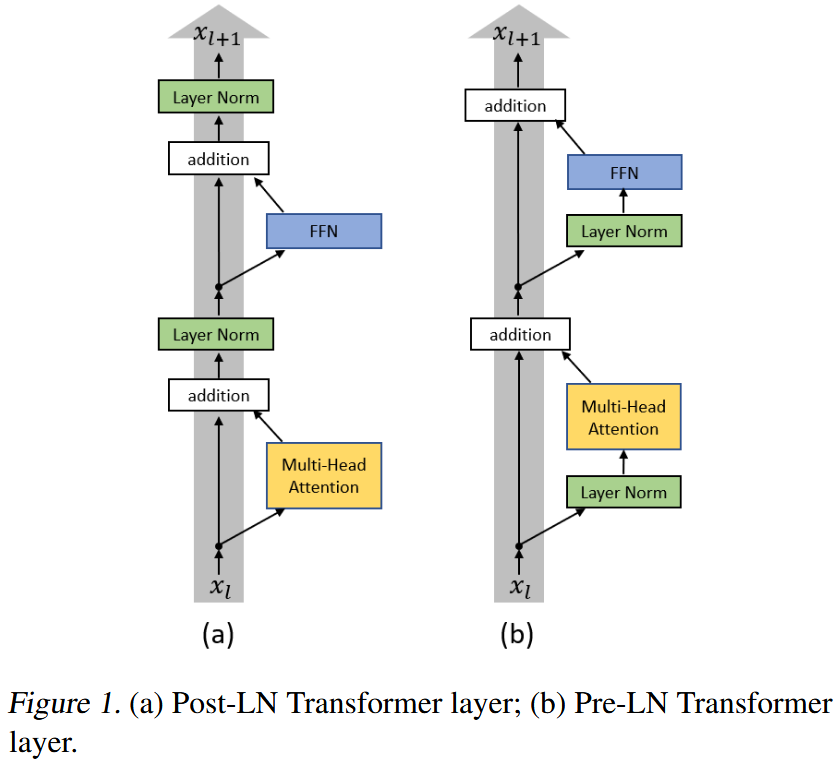
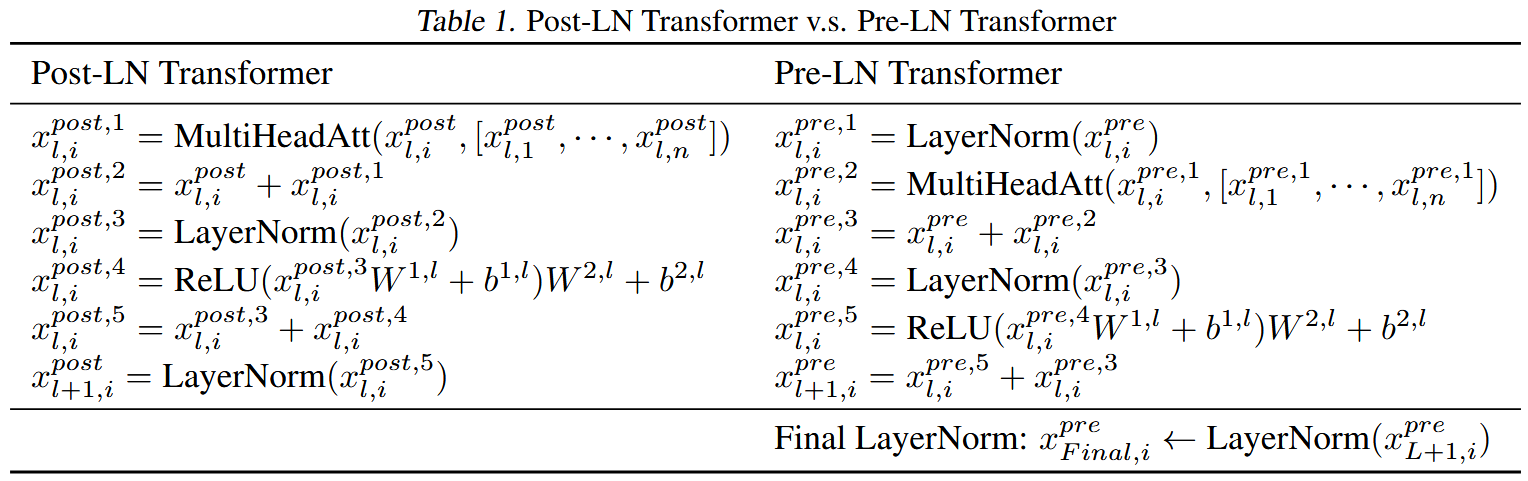
- Post-LN:Transformer 原始论文中提出的架构。
- 在每个子层(多头自注意力或前馈网络)的输出之后,先进行残差连接(addition),然后进行 Layer Normalization。
- 缺陷:对于非常深的网络,残差路径中的 Layer Normalization 会对梯度传播造成影响,可能会有梯度消失的问题。具体而言,在训练初期,由于参数还未收敛,某些层的输出可能非常大,导致 Layer Normalization 后的值被压缩到一个很小的范围,从而导致梯度消失。
- 公式:从左侧表格中的
Post-LN Transformer列看到,Layer Normalization 位于残差相加之后。
- Pre-LN Transformer:目前后来被广泛采用的架构。
- Layer Normalization 被移到了每个子层的输入之前。
- 核心思想:确保主残差信号路径(Main Residual Signal Path)不受 Layer Normalization 的影响。如图所示,从输入 $x_l$ 到输出 $x_{l + 1}$ 的残差路径是一个纯粹的加法,没有额外的归一化操作。
- 优点:这种结构对梯度流非常友好。由于残差连接路径是“干净”的,梯度可以直接无阻碍地从深层传播到浅层,缓解了训练深层网络时的梯度消失问题。这使得模型可以训练得更深、更稳定,同时收敛速度更快。
- 公式:可以从右侧表格中的
Pre-LN Transformer列看到,Layer Normalization 位于计算之前。
LayerNorm vs RMSNorm
- LayerNorm:Transformer 原始论文中使用的归一化方法。它通过减去均值并除以标准差来对输入进行归一化。
公式:
\[y = \frac{x - E[x]}{\sqrt{Var[x] + \varepsilon}} \cdot \gamma + \beta\]- 引入了两个可学习的参数:$\gamma$(缩放)和 $\beta$(偏置)。
代表模型:GPT-1/2/3、OPT、GPT-J、BLOOM 等早期和中期的 LLM 都采用了这种方法。
- RMSNorm:更简单的归一化方法,它只除以向量的 RMS(均方根)。
公式:
\[y = \frac{x}{\sqrt{\Vert x \Vert_2^2 + \varepsilon}} \cdot \gamma\]- 它不减去均值,也不添加偏置项 $\beta$,因此只有缩放参数 $\gamma$。
- 代表模型:许多现代 LLM,如 LLama、PaLM、Chinchilla 和 T5。
- RMSNorm 的性能优势
- FLOPs 不等于运行时间:这是一条重要的经验法则。尽管 RMSNorm 减少了 FLOPs,但这并不是它更快的真正原因。
- 运行时间瓶颈:实际运行时间通常由数据移动(Data movement)决定,而不是计算量。虽然统计归一化操作的 FLOPs 很少,但它在运行时却占用了 25.5% 的时间。这是因为归一化操作需要将整个向量读入内存,然后进行计算,这涉及大量的数据 I/O。
- 因为 RMSNorm 的计算更简单,它能更高效地完成数据加载和计算。虽然这几毫秒的节省在单次计算中不显眼,但在整个深度网络中累积起来,就会带来显著的加速效果。
去除偏置项
- 现代 Transformer 模型普遍去掉了偏置项(bias terms)。
原始 Transformer 的 FFN 公式:
\[\text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2\]现代 Transformer 的 FFN 公式:
\[\text{FFN}(x) = \sigma(xW_1)W_2\]- 原因
- 减少内存开销。
- 优化稳定性:偏置项通常会增加模型的复杂性。去掉偏置项并不会显著影响模型的性能,甚至在某些情况下,能让训练过程更稳定、收敛得更快。
激活函数
- ReLU
- 模型:原始 Transformer 模型、T5、Gopher、Chinchilla、OPT。
公式:
\[\text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2\]
- GeLU
- 将输入值乘以一个基于其在高斯分布中的概率的“门控”值。
- 模型:GPT-1/2/3、GPT-J、GPT-Neox 和 BLOOM。
公式:
\[\begin{align*} \text{FFN}(x) &= \text{GELU}(xW_1)W_2 \\ \text{GELU}(x) &:= x \Phi(x) \end{align*}\]
- GLU(门控线性单元)家族
- 引入了一个“门控”机制,能更精细地控制信息的流动。
- 将输入值分成两部分,其中一部分用于激活,另一部分则作为“门”,用于决定激活后的信息应该如何被传递。
例子:从 ReLU 到 ReGLU,通过一个线性项(引入额外参数 $V$)增强原来的线性变换 + ReLU 组合。
\[\begin{align*} \max(0, xW_1) &\rightarrow \max(0, xW_1) \otimes (xV) \\ \text{FFN}_{\text{ReGLU}}(x) &= (\max(0, xW_1) \otimes xV) W_2 \end{align*}\]
- GeGLU
- 模型:T5 v1.1、mT5、LaMDA、Phi-3、Gemma 2、Gemma 3。
公式:
\[\text{FFN}_{\text{GEGLU}}(x, W, V, W_2) = (\text{GELU}(xW) \otimes xV) W_2\]
- SwiGLU
- 模型:LLama 1/2/3、PaLM、Mistral、OlMo 和 2023 年后的大多数模型。
公式:
\[\begin{align*} \text{FFN}_{\text{SwiGLU}}(x, W, V, W_2) &= (\text{Swish}(xW) \otimes xV) W_2 \\ \text{Swish} &= x \cdot \text{Sigmoid}(x) \end{align*}\]
注意力机制改进
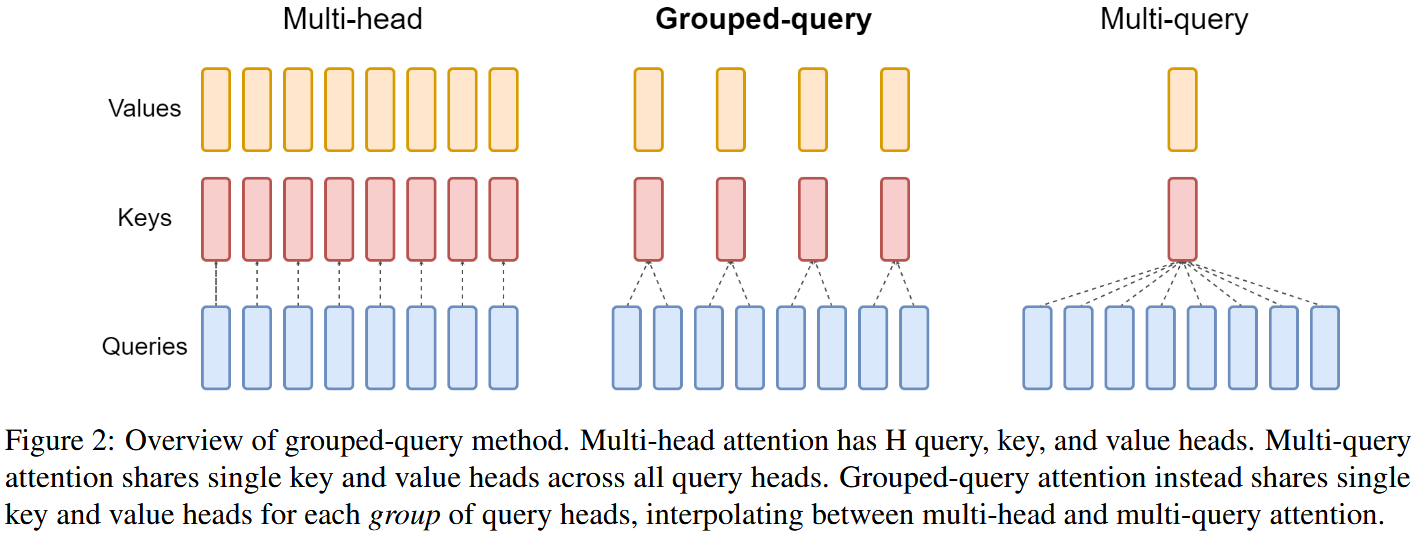
图片来源:GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
- 多查询注意力 (Multi-Query Attention, MQA)
- 所有的注意力头共享同一组 Key ($K$) 和 Value ($V$) 投影。
- 显著减少了推理时的内存占用(KV 缓存),从而降低了内存访问的开销。
- 有时会带来微小的性能(PPL)下降。
- 分组查询注意力 (Grouped-Query Attention, GQA)
- MQA 的一个扩展,介于 MQA 和标准多头注意力之间。
- 不共享所有的 Key/Value 投影,而是使用比查询头数量更少的 K/V 投影,但大于一个。
- 在保持较高的推理效率(因为 KV 缓存更小)的同时,几乎没有性能损失。
- 稀疏/滑动窗口注意力 (Sparse / Sliding Window Attention)
- 避免对整个上下文进行昂贵的二次方计算,在表达能力和运行时效率之间取得平衡。
- 稀疏注意力:只关注上下文中的部分内容。GPT-3 采用了这种方法。
- 滑动窗口注意力:只让每个词关注其前后一个固定大小窗口内的内容。Mistral 模型使用了这种方式,并通过网络深度来扩展有效上下文。
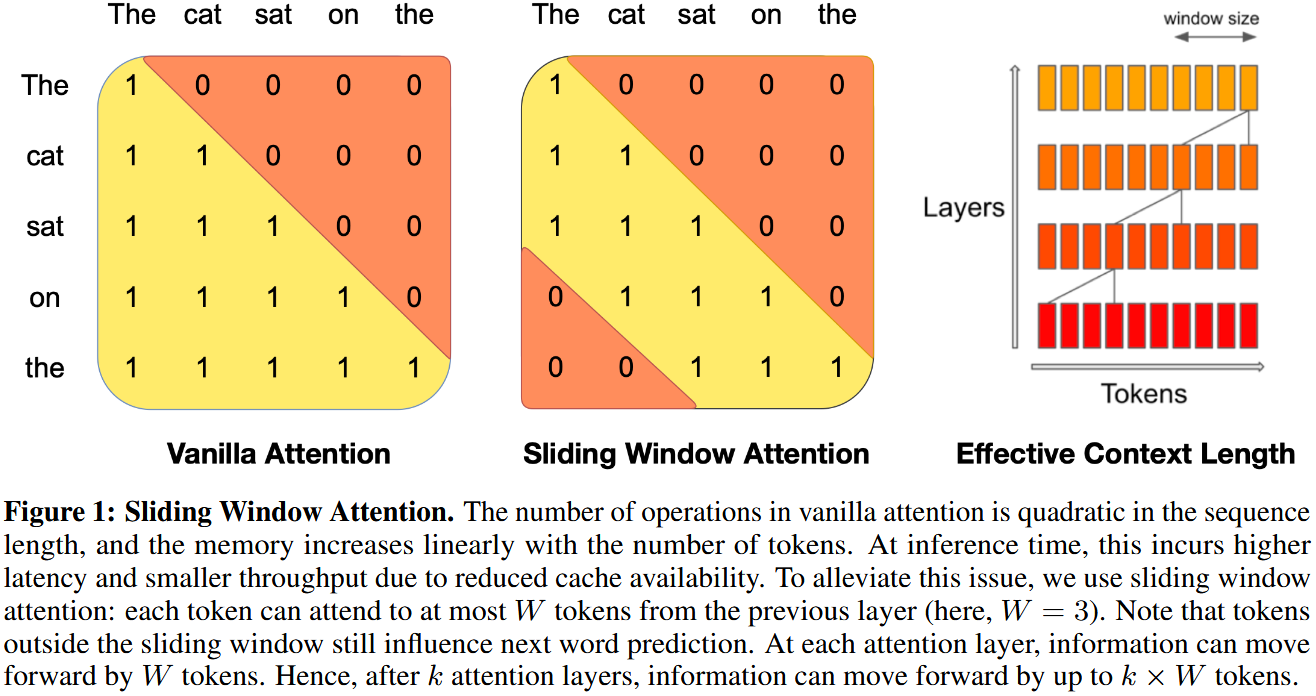
图片来源:Mistral 7B
- 全注意力与局部注意力交错 (Interleaving ‘Full’ and ‘LR’ Attention)
- 将全注意力层和局部(低秩)注意力层交替使用的方法。
- 例子:Cohere Command A 模型,该模型每隔四层使用一个全注意力层。这种方法旨在平衡局部注意力的效率和全注意力捕捉全局信息的能力。
混合专家模型 MoE(Mixture of Experts)
定义
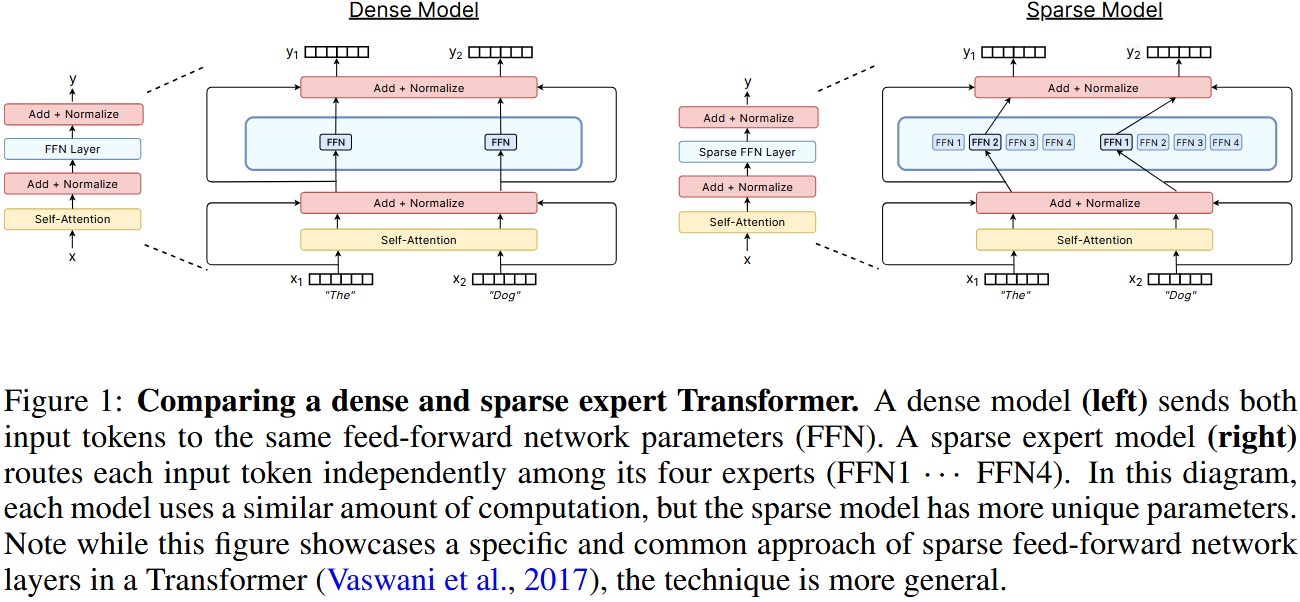
- MoE 是一种稀疏模型。它用多个前馈网络(FFNs)和一个选择层来取代传统的单个大型前馈网络层。
- 对于给定的输入,MoE 模型只会激活其中的一小部分“专家”(即 FFNs)进行计算,而不是像密集模型那样激活所有参数。
优势
- 性能优越:在相同的计算量(FLOPs)下,MoE 模型可以使用更多的参数,从而获得更好的性能。这使得它们在与参数量相当的密集模型竞争时具有优势。
- 训练速度快:MoE 模型的训练速度通常比同等性能的密集模型快得多。
- 并行化能力强:MoE 架构可以很容易地在多台设备上进行并行化,每个设备可以托管不同的专家,从而实现模型并行,提高了训练和推理的效率。
路由策略
- 路由函数的核心思想:选择 Top K。大多数 MoEs 选择了下图中最左侧的方法,即每个 Token 会被分配给 $K$ 个专家。
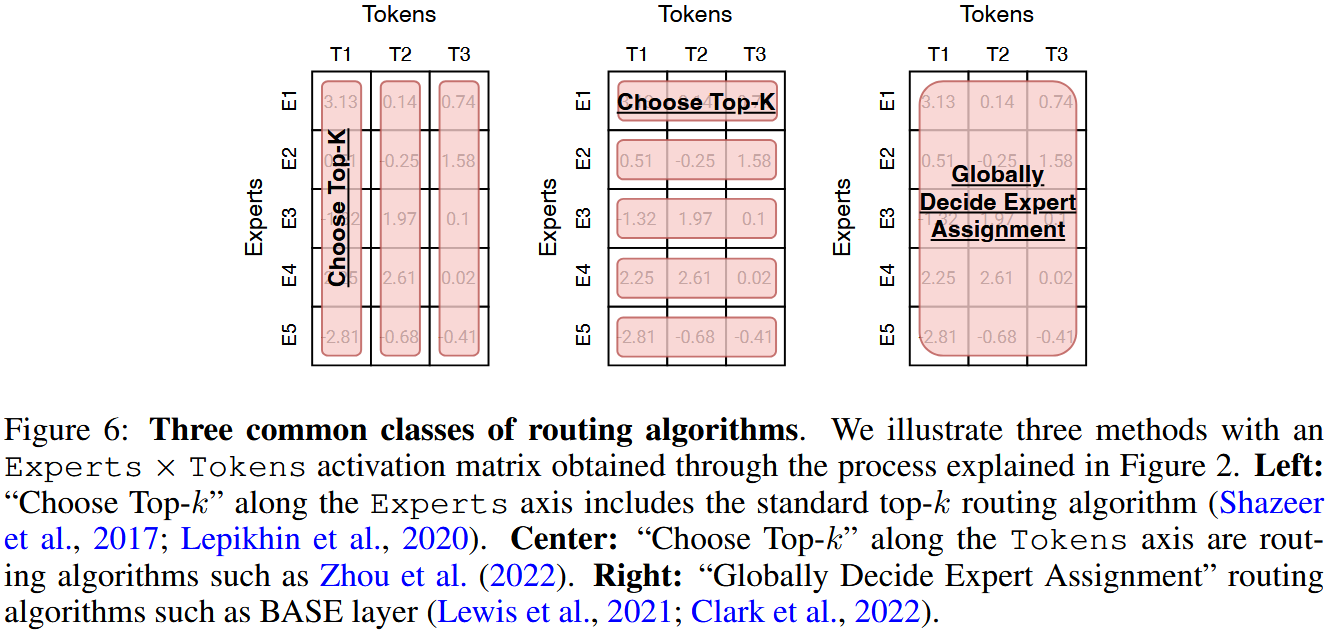
- Top-K 路由算法
- 大多数模型采用 Top-K 算法:Switch Transformer ($K=1$)、Gshard ($K = 2$)、Grok ($K = 2$)、Mixtral ($K = 2$)、Qwen ($K = 4$)、DBRX ($K = 4$)、DeepSeek ($K = 7$)。
以 DeepSeek MoE 的实现方法为例:共享专家 + 路由专家
\[\begin{align*} \mathbf{h}_t^l &= \sum_{i = 1}^N \left(g_{i, t} \text{FFN}_i \left(\mathbf{u}_t^l \right)\right) + \mathbf{u}_t^l, \\ g_{i, t} &= \begin{cases} s_{i, t},\quad &s_{i, t} \in \text{TopK}(\{s_{j, t}\vert 1\leq j \leq N\},K), \\ 0,\quad &\text{otherwise}, \end{cases}\\ s_{i, t} &= \text{Softmax}_i\left(\mathbf{u}_t^{l^T}\mathbf{e}_i^l \right). \end{align*}\]- 上述公式 $s_{i, t}$ 逻辑回归输出的门控函数 $g_{i, t}$ 选择的概率。
- DeepSeek V1/2, Grok, Qwen 使用了类似路由机制。
- Mixtral, DBRX, DeepSeek V3 将
Softmax归一化放到了TopK选择后面。
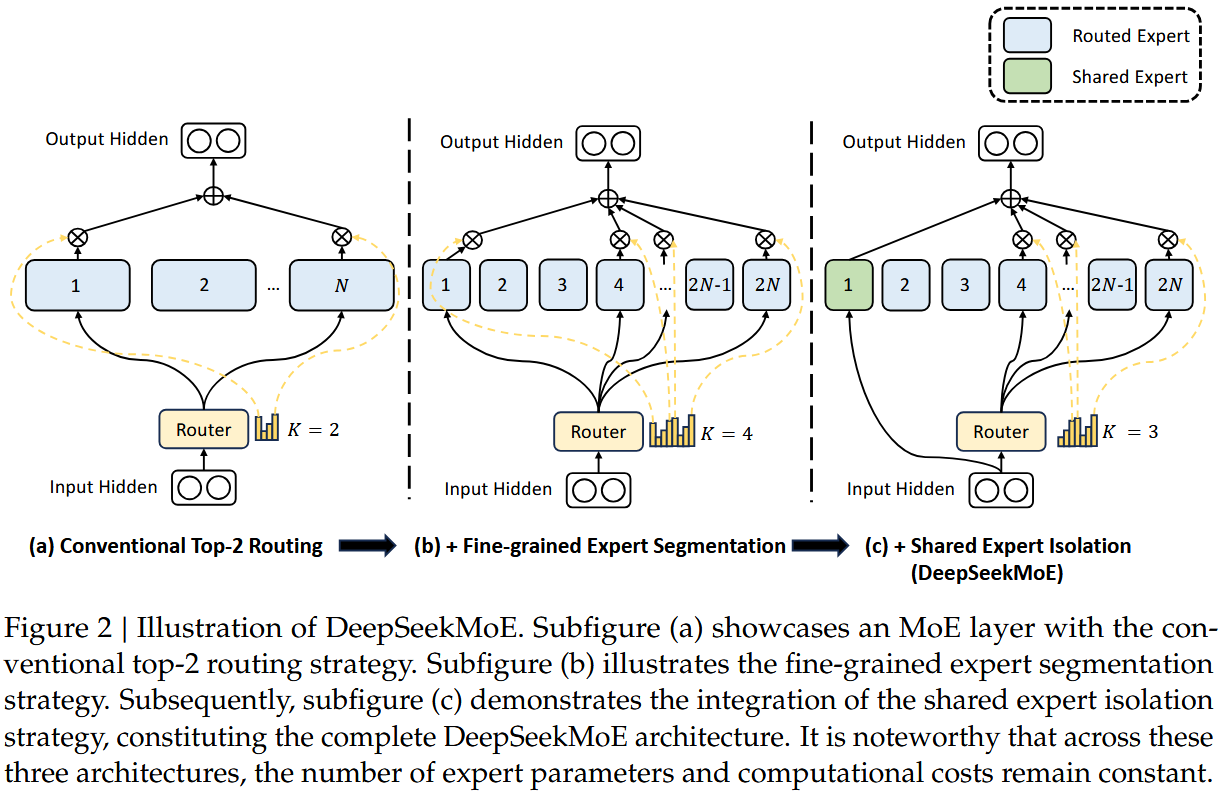
图片来源:DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
- 细粒度专家分割
- 解决传统 MoE 的问题
- 专家数量有限:在计算资源受限的情况下,模型中能容纳的专家总数(
K)是有限的。 - 专家过载与知识冲突:由于专家少,每个被激活的专家就不得不处理大量被路由过来的、五花八门的
token。这些token可能代表完全不同类型的知识(例如,一个token是关于“天体物理”的,下一个token是关于“蛋糕烘焙”的)。 - 学习困难:一个专家神经网络很难在其同一组参数中同时完美地学习和表征多种截然不同的知识。这会导致知识冲突,使得专家的学习效率低下, specialization(专业化)程度不高。
- 专家数量有限:在计算资源受限的情况下,模型中能容纳的专家总数(
- 核心思想:既然一个“大专家”难以学习多种知识,那就把“大专家”拆成多个“小专家”,让每个“小专家”去专注于学习更精细、更单一的知识点。
- 实现方法
- 分割专家
- 在一个标准的 MoE 模型中,每个专家 FFN 本身是一个较大的神经网络(例如,输入维度
d_model,中间有一个非常大的隐藏层d_ffn(如 4 倍d_model),再输出回d_model)。 - 现在,将每个这样的“大专家”在宽度上平均分割成
m个“小专家”。具体来说,就是把原来巨大的中间隐藏层维度d_ffn减小到原来的1/m(即d_ffn / m)。 - 于是,原来的 1 个大专家 $\rightarrow$ 变成了
m个小专家。这些小专家共同构成了一个“专家组”,但它们彼此参数独立。
- 在一个标准的 MoE 模型中,每个专家 FFN 本身是一个较大的神经网络(例如,输入维度
- 保持计算量不变
- 由于每个小专家的计算量(FLOPs)大约变成了原来的
1/m(因为最耗计算的矩阵变小了)。 - 为了在处理同一个
token时保持总计算成本不变,我们不再只激活 1 个原始大专家,而是激活m个新的小专家。 1个大专家的计算成本 ≈m个小专家的计算成本。
- 由于每个小专家的计算量(FLOPs)大约变成了原来的
- 分割专家
- 解决传统 MoE 的问题
训练
- MoE 训练的主要挑战
- 梯度不可导:路由器的决策过程(选择哪个专家)是离散的。传统的基于梯度的反向传播算法难以直接应用于这种离散决策,这使得路由器本身的训练成为一个难题。
- 负载不平衡:在训练过程中,由于数据分布或路由器自身的偏好,一些专家可能会被过度使用,而另一些则几乎没有被使用。这种专家利用率不均导致了计算资源的浪费和模型性能的下降。
- 解决挑战的三种方法:后两种方法在实践中常用。
- 强化学习 (Reinforcement learning) 来优化门控策略: 将门控网络的决策过程看作是一个“智能体”在做决策,并使用强化学习来训练它,以最大化某种奖励(例如,模型的准确性)。这种方法在理论上可行,但在实践中实现起来非常复杂,训练通常不稳定。
- 随机扰动 (Stochastic perturbations): 在门控决策中加入随机噪声,即 Noisy Top-K Gating 机制。通过引入噪声,门控决策变得“软”了一些,使得训练过程更加平滑和稳定,同时有助于解决专家利用不均衡的问题。
- 启发式平衡损失 (Heuristic balancing losses): 这是一种常用的工程技巧,它在训练的总损失函数中添加一个额外的“平衡”项。这个损失项的目标是惩罚那些只使用少数专家的行为,从而鼓励门控网络更均匀地利用所有专家。这有助于确保所有专家都能得到充分训练。
随机扰动:以 Noisy Top-K Gating 为例
- 机制
- Gating(门控):决定哪些专家可以被激活。它会为每个专家计算一个分数,这个分数代表该专家处理当前输入数据的“相关性”。
- Top-K(前 $K$ 个): 这意味着门控网络只选择分数最高的 $K$ 个专家来处理数据。例如,如果 $K = 2$,它就会选择分数最高的前两个专家。
- Noisy(噪声): 这是 Noisy Top-K Gating 的关键创新点。在计算专家分数时,它会人为地引入随机噪声。目的如下:
- 缓解专家不平衡: 如果没有噪声,门控网络可能会倾向于总是选择少数几个“表现最好”的专家,导致其他专家得不到足够的训练,最终变得无效。引入噪声后,即使某个专家的分数不是最高,它也有机会被选中,这使得模型的训练更加均衡。
- 提高模型的泛化能力: 噪声可以看作是一种正则化手段。它能让模型在训练时探索更多可能性,避免过度依赖于固定的专家组合,从而提高模型的泛化能力。
公式:参考 Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer 。
\[\begin{align*} G(x) &= \text{Softmax}(\text{KeepTopK}(H(x), k)) \\ H(x)_i &= (x \cdot W_g)_i + \text{StandardNormal}() \cdot \text{Softplus}((x \cdot W_{\text{noise}})_i) \\ \text{KeepTopK}(v, k)_i &= \begin{cases} v_i,\quad &\text{if }v_i\text{ is in the top }k\text{ elements of }v,\\ -\infty,\quad &\text{otherwise}. \end{cases} \end{align*}\]- 门控函数 $G(x)$:定义了最终的门控输出。它首先计算一个中间值 $H(x)$,然后通过
KeepTopK函数保留其中最大的 $k$ 个元素,将其他元素设置为负无穷,最后对结果应用Softmax函数。这使得被选中的 $k$ 个专家的权重之和为 1,而未被选中的专家权重为 0。 - 扰动函数 $H(x)$:定义了每个专家(索引为 $i$)的分数。它由两部分组成:
- 专家分数:$x\cdot W_g$ 是标准的门控网络计算,表示了输入 $x$ 与每个专家之间的相关性。
- 随机扰动:\(\text{StandardNormal}() \cdot \text{Softplus}((x\cdot W_{\text{noise}})_i)\) 是噪声部分。它引入了一个服从标准正态分布的随机数
StandardNormal(),并乘以一个由 $x\cdot W_{\text{noise}}$ 计算出的值(通过Softplus函数确保这个值是非负的)。这个随机扰动使得每次计算的分数都会略有不同,从而避免门控网络总是选择相同的专家。
KeepTopK函数:硬性地选择前 $k$ 个专家。
- 门控函数 $G(x)$:定义了最终的门控输出。它首先计算一个中间值 $H(x)$,然后通过
- 优势
- 专家更具鲁棒性:由于引入了随机噪声,门控网络不会过度依赖于少数几个“表现最好”的专家。即使某个专家在特定情况下不是最优选择,它也有机会被选中。这有助于所有专家都得到足够的训练,使得整个系统更加健壮和鲁棒。
- 模型学习如何排序 $k$ 个专家:通过
Softmax操作,模型不仅学习如何挑选专家,还学习如何对它们进行加权排序。这使得模型能够更精细地控制不同专家在特定任务中的贡献,而不是简单地给它们分配相同的权重。
启发式平衡损失
- Switch Transformer 的解决方案:添加辅助损失项(auxiliary loss)。
- 主损失(总损失):模型的总损失 = 正常的预测损失 $+\ \alpha\ \cdot$ 辅助平衡损失。
辅助平衡损失:
\[\begin{align*} \text{loss} &= \alpha \cdot N \cdot \sum_{i = 1}^N f_i \cdot P_i \\ f_i &= \frac{1}{T} \sum_{x \in \mathcal{B}} \mathbb{1}\{\text{argmax } p(x) = i\} \\ P_i &= \frac{1}{T} \sum_{x\in \mathcal{B}} p_i(x) \end{align*}\]- $f_i$(专家分派分数):$f_i$ 是当前 batch 中,被硬性分派给专家 $i$ 的 token 的比例。它反映了专家 $i$ 在当前 batch 中被实际使用的频率。
- $P_i$(专家路由概率):$P_i$ 是当前 batch 中,门控网络分配给专家 $i$ 的平均概率。它反映了专家 $i$ 被路由的期望。
- 为什么将两者相乘?
- 如果一个专家实际使用频率很高($f_i$ 很大),同时它的路由概率也很高($P_i$ 很大),那么 $f_i \cdot P_i$ 的值就会很大,从而导致平衡损失增大。
- 反之,如果专家被均匀使用,那么所有的 $f_i$ 和 $P_i$ 的值都会接近,其乘积会保持在一个较小的水平,从而使得平衡损失减小。
- 核心思想
“更频繁的使用会带来更强的下调(downweighting)”:通过对损失函数求导,可以看到,当一个专家被更频繁地使用时,它的梯度就会变得更大。
\[\frac{\partial \text{ loss}}{\partial p_i(x)} = \frac{\alpha N}{T^2}\sum_{x \in \mathcal{B}} \mathbb{1}\{\text{argmax } p(x) = i\}\]效果:更大的梯度会抑制门控网络继续将输入路由给这个“热门”专家。类似一个负反馈循环:当某个专家被用得太多时,这个平衡损失就会“惩罚”它,迫使门控网络去寻找和使用其他专家。
- DeepSeek V1-2 的解决方案:两种平衡机制。
- 按专家平衡 (Per-expert balancing):与 Switch Transformer 类似。
- 按设备平衡 (Per-device balancing):
- 在大型分布式系统中,每个设备可能承载了不止一个专家。即使每个专家都被均匀使用了,如果某些设备上的专家总是比其他设备上的专家处理更多的 token,那么这些设备就会过载,导致负载不均衡。按设备平衡就是为了解决这个问题。
- 设备平衡机制类似专家平衡机制,但其损失函数的计算是在设备级别上进行聚合。
DeepSeek V3 的解决方案:在专家平衡机制的基础上引入专家级偏差(Per-expert biases)。
\[g'_{i, t} = \begin{cases} s_{i, t},\quad &s_{i, t} + b_i \in \text{TopK}(\{s_{j, t} + b_j \vert 1\leq j \leq N_r \}, K_r), \\ 0,\quad &\text{otherwise}. \end{cases}\]- 上述公式描述了路由器的输出 \(g'_{i, t}\)。它在传统的专家分数 \(s_{i, t}\) 上加上了一个偏差项 \(b_t\),然后选择前 \(K_r\) 个专家。
- 通过在线学习调整这些偏差项,模型可以直接“偏向”那些使用频率较低的专家,让它们更有可能被选中。这是一种主动的、直接的平衡方法,因为它不是通过惩罚损失来间接平衡,而是直接调整路由器的决策。
系统视角:并行化
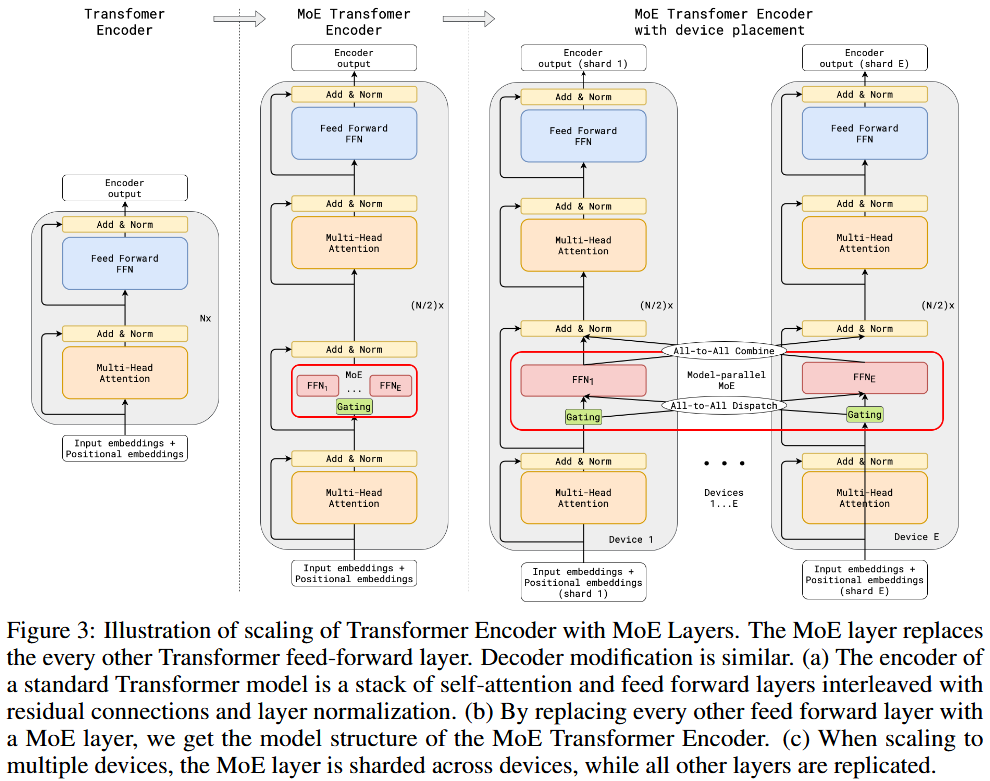
图片来源:GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
- MoE 的天然并行化优势
- 每个专家(Expert)都是一个完整的前馈网络(FFN),通常这个 FFN 的大小可以完全放入单个设备(如一个 GPU 或 TPU)的内存中。
- 传统的 Transformer 模型需要将整个 FFN 层进行模型并行,将其拆分到多个设备上。但 MoE 模型由于其稀疏性,可以轻松地将不同的专家放置在不同的设备上,从而实现高效的专家并行。
- 这种“每个专家可以装入一个设备”的特性,使得 MoE 模型特别适合大规模分布式训练。

图片来源:Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
- 多种并行策略组合
- Data Parallelism (数据并行):最基本的并行策略。每个设备都有一份完整的模型副本,但只处理一小部分数据。
- Model Parallelism (模型并行):当单个模型的参数量太大,无法放入一个设备时,就需要将模型本身进行拆分。例如,将 Transformer 的不同层或单个层内的不同部分分配给不同的设备。
- Expert and Data Parallelism (专家并行和数据并行):这是 MoE 训练的典型配置。
- 专家并行:不同的设备负责处理不同的专家。
- 数据并行:每个设备上的专家又处理整个批次中的一部分数据。
- Expert, Model and Data Parallelism (专家、模型和数据并行):最复杂的并行化策略。当单个专家本身都非常大时,就需要将一个专家内部再进行模型并行。
- 比如,一个专家网络(FFN)被拆分到多个设备上。
- 不同的专家组又被分配给不同的设备组。
- 每个设备组再处理整个批次的一部分数据。
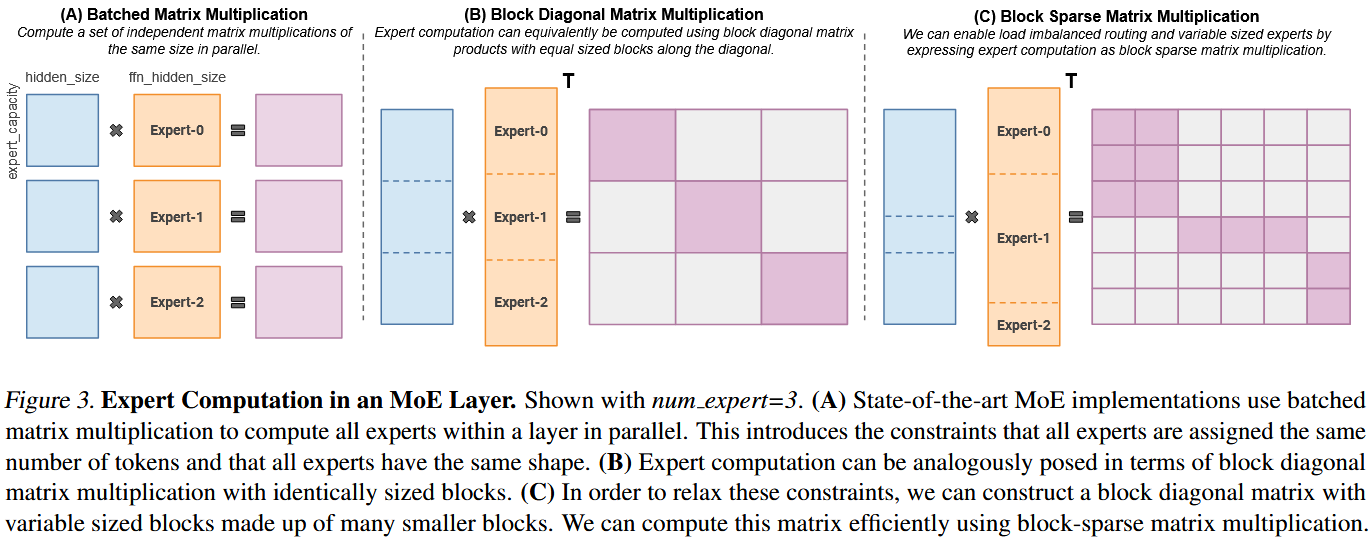
图片来源:MegaBlocks: Efficient Sparse Training with Mixture-of-Experts
- 路由机制并行化
- 路由并行化计算的挑战:MoE 的稀疏性使得计算变得复杂。与传统的密集计算不同,MoE 模型的计算依赖于路由器选择的少数几个专家。这需要一种特殊的、高效的稀疏矩阵乘法方法。
- 三种矩阵乘法模式
- 批处理矩阵乘法 (Batched Matrix Multiplication)
- 路由器将 token 分配给不同的专家,然后每个专家分别对它分到的 token 进行独立的矩阵乘法。
- 类似同时进行多场小规模的计算。尽管这些计算可以并行执行,但由于它们是独立的,需要额外的管理和同步,可能导致效率低下。
- 块对角矩阵乘法 (Block Diagonal Matrix Multiplication)
- 更高效的表示方式。它将所有专家的计算合并成一个大的矩阵乘法。
- 这个大矩阵是一个块对角矩阵:矩阵的对角线上是每个专家的权重矩阵,而其他部分都是零。
- 这种表示使得计算可以由专门的硬件(如 GPU 或 TPU)高效执行,但它有一个局限性:它假设所有专家处理的 token 数量相等,这在实际中很难实现。
- 块稀疏矩阵乘法 (Block Sparse Matrix Multiplication)
- 最能反映现实情况的表示方式,也是现代 MoE 模型所采用的方法。
- 这个矩阵是块稀疏的:只有被选中的专家对应的“块”是非零的,而那些未被选中的专家对应的“块”则为零。
- 这种方法可以处理负载不均衡的路由和可变大小的专家,因为它只计算那些实际需要的矩阵块。这使得它既能高效利用硬件,又能适应 MoE 模型的稀疏和动态特性。
- 批处理矩阵乘法 (Batched Matrix Multiplication)
- 现代的深度学习库(如 MegaBlocks)能够将 MoE 的稀疏计算表示为优化的块稀疏矩阵乘法。
训练及微调的工程技巧
- 训练
- 问题:MoE 在使用 BF16 精度时存在数值稳定性问题,尤其是在
Softmax函数中。由于指数函数的特性,一个微小的输入扰动(例如一个舍入误差)可能导致Softmax输出的巨大差异。 - 解决方案:为了解决这个稳定性问题,建议对专家路由(expert router)使用 FP32 精度,有时还会结合使用辅助损失(auxiliary loss 或 z-loss)。
- 问题:MoE 在使用 BF16 精度时存在数值稳定性问题,尤其是在
- 微调
- 问题:稀疏 MoE 模型在较小规模的微调数据集上容易过拟合,而密集模型则更稳定。
- Zoph et al. 的解决方案:微调非 MoE 的 MLP。
- DeepSeek 的解决方案:使用大规模数据进行微调,例如 1.4M SFT(监督式微调)数据。
Upcycling
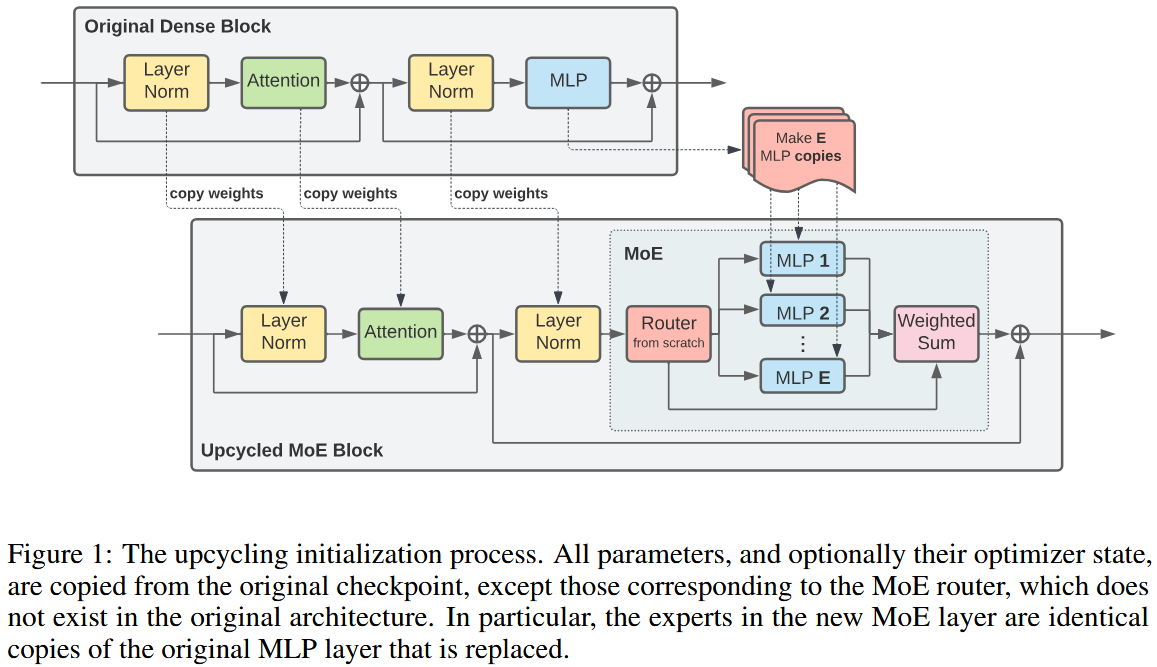
图片来源:Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints
- Upcycling 是一种将已有的、预训练好的密集模型高效转换为稀疏 MoE 模型的方法。
- 核心机制
- 复制 MLP:将原始密集模型中的 MLP 模块的权重进行复制,用这些权重来初始化 MoE 模块中的所有专家。
- 重新训练路由器:MoE 模块中的路由器是随机初始化的,需要从头开始学习如何将输入令牌路由到不同的专家。
- 优势:利用了预训练密集模型已学习到的知识,因此在额外的预训练时间上,MoE 模型可以更快地达到更高的性能。
DeepSeek 架构演进
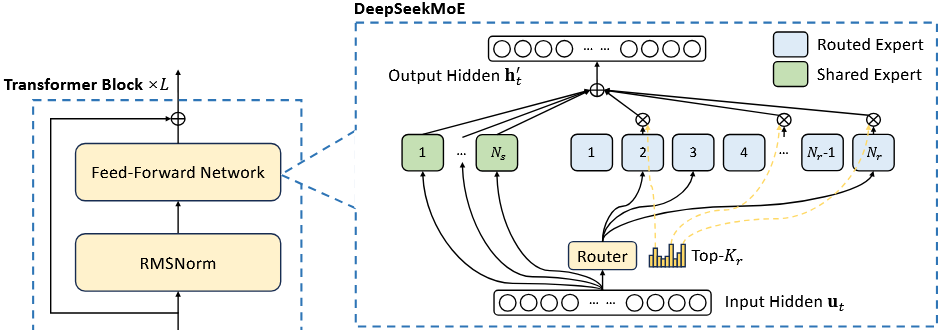
DeepSeek MoE V1
- 架构
- 参数:16B - 2.8B 激活。
- 专家结构:2 个共享专家 + 64 个路由专家(细粒度分割)。
- 激活专家:每次激活 6 个专家(4 个路由专家 + 2 个共享专家)。
- 路由方式:标准 Top-K 路由。
- 关键技术
路由公式
\[g_{i,t} = \begin{cases} s_{i,t}, & s_{i,t} \in \text{TopK}(\{s_{j,t}|1 \leq j \leq N\}, K), \\ 0, & \text{otherwise}. \end{cases}\]平衡机制:标准辅助损失(专家级 + 设备级平衡)
\[\mathcal{L}_{\text{ExpBal}} = \alpha_1 \sum_{i=1}^{N} f_i P_i\]
DeepSeek MoE V2
- 架构
- 参数:236B - 21B 激活。
- 专家结构:2 个共享专家 + 160 个路由专家(更细粒度)。
- 激活专家:每次激活 10 个专家。
- 路由新特性:Top-M 设备路由。
- 关键技术
- 设备限制路由
- 步骤
- 首先根据每个设备上专家的“亲和力得分”(affinity scores)选择出得分最高的 $M$ 个设备。
- 在这些设备的专家中进行 Top-K 选择。
- $M = 3$ 时性能与无限制路由相当。
- 优势
- 减少跨设备通信: 确保了大部分(甚至所有)计算任务都在少数几个设备上完成,显著降低了数据传输的开销。
- 提升推理效率: 通过减少网络通信,可以提高 MoE 模型的分布式推理和训练效率。
- 步骤
- 通信平衡损失
- 发送均衡(Sending Out)
- 该机制首先确保每个设备最多只发送
MT个隐藏状态到其他设备。这里的M可能是之前提到的设备数量,而T代表 token 的数量。 - 这保证了没有单个设备因为承担过多任务而成为瓶颈。
- 该机制首先确保每个设备最多只发送
- 接收均衡(Receiving In)
- 同时,通信均衡损失鼓励每个设备从其他设备接收大约
MT个隐藏状态。 - 这意味着每个设备不仅仅是“付出”,也要“收获”,从而实现双向的、对等的通信。
- 同时,通信均衡损失鼓励每个设备从其他设备接收大约
公式
\[\mathcal{L}_{\text{CommBal}} = \alpha_2 \sum_{i=1}^{D} f_i' P_i'\]- 平衡设备间的输入输出通信量。
- 确保每个设备发送/接收约
M个隐藏状态。
- 发送均衡(Sending Out)
- 设备限制路由
DeepSeek MoE V3
- 架构革新
- 参数:671B - 37B 激活。
- 专家结构:1 个共享专家 + 256 个路由专家。
- 激活专家:每次激活 8 个专家。
- 路由创新:
Sigmoid+Softmax组合。
- 关键技术
新型路由机制
\[\begin{align*} s_{i,t} &= \text{Sigmoid}(u_t^T e_i) \\ g_{i,t}' &= \begin{cases} s_{i,t}, & s_{i,t} \in \text{TopK}(\{s_{j,t}|1 \leq j \leq N_r\}, K_r), \\ 0, & \text{otherwise}. \end{cases} \end{align*}\]无辅助损失的序列级辅助平衡(Aux-loss-free + seq-wise aux)
\[g_{i,t}' = \begin{cases} s_{i,t}, & s_{i,t} + b_i \in \text{TopK}(\{s_{j,t} + b_j|1 \leq j \leq N_r\}, K_r), \\ 0, & \text{otherwise}. \end{cases}\]- 每专家权重加上可学习的偏置项。
- 在线学习偏置:使负载均衡不再依赖显式辅助损失。
- 补充序列级平衡损失:防止单序列内极端不平衡。
架构优化策略
1 2 3 4 5
训练效率 ← MTP(多令牌预测) ↑ 模型能力 ← MoE(混合专家) ↓ 推理效率 ← MLA(潜在注意力)
| 维度 | MLA | MTP |
|---|---|---|
| 主要目标 | 优化推理内存效率 | 优化训练效率 |
| 解决瓶颈 | 内存带宽瓶颈(KV 缓存) | 训练收敛速度 |
| 应用阶段 | 主要影响推理阶段 | 主要影响训练阶段 |
| 技术范畴 | 注意力机制优化 | 训练目标优化 |
| 在 DeepSeek 中 | 核心推理优化技术 | 辅助训练加速技术 |
创新 1:MLA(多头潜在注意力)
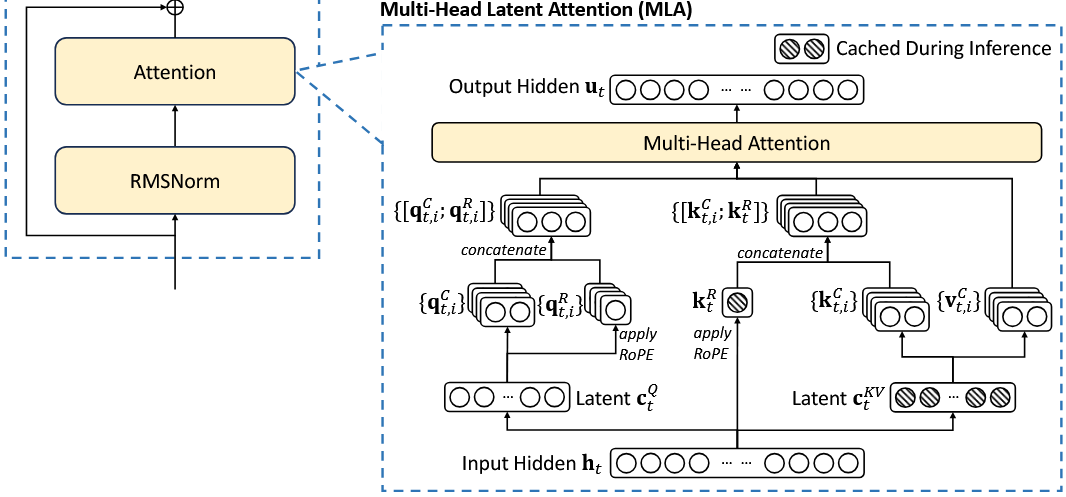
- 目的:解决推理时的 KV 缓存内存瓶颈,实现更高效的长序列推理。
- 核心思想:将 $Q$、$K$、$V$ 表示为低维潜在激活的函数。具体来说,不直接缓存巨大的 $K$ 和 $V$ 矩阵,而是缓存一个低维的潜在状态,在需要时动态重建 $K$ 和 $V$。
- 步骤
压缩阶段
\[c_t^{KV} = W^{DKV} \mathbf{h}_t\]- 将隐藏状态投影到低维潜在空间。
- $c_t^{KV}$ 的维度远小于原始 $K + V$。
重建阶段
\[\mathbf{k}_t^C = W^{UK} c_t^{KV}, \quad \mathbf{v}_t^C = W^{UV} c_t^{KV}\]- 从潜在状态动态重建 $K$ 和 $V$。
Query 处理(可选)
\[c_t^Q = W^{DQ} \mathbf{h}_t, \quad q_t^C = W^{UQ} c_t^Q\]
- RoPE 兼容性问题
- 问题:旋转位置编码破坏线性可合并性。
- 解决方案:保留部分非潜在 $K$ 维度专门用于 RoPE。
- 优势:KV 缓存时只需存储 $c_t^{KV}$,大幅减少内存占用。
创新 2:MTP(多令牌预测)
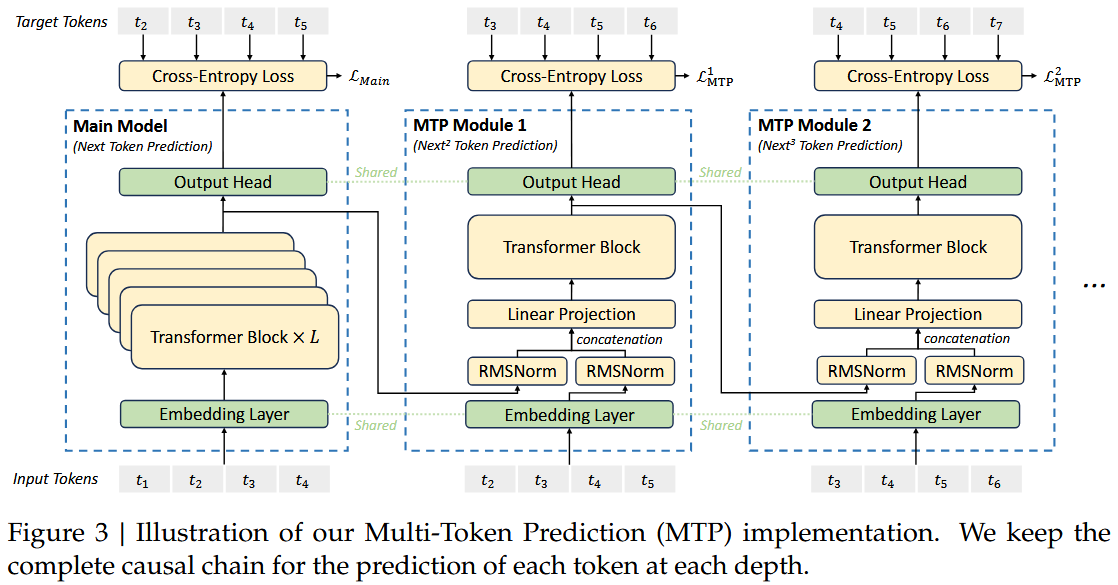
- 目的:提升训练效率,让模型在一次前向传播中学习预测多个未来令牌。
- 核心思想:传统的语言模型只预测下一个令牌,MTP 让模型同时预测后续多个令牌。
- 实现方式
- 使用小型、轻量级的预测头来预测未来多个时间步。
- 在 DeepSeek-V3 中仅预测一个令牌 ahead(相对保守的实现)。
- 参考 EAGLE 等架构的思想。
- 优势
- 训练效率提升:每个令牌提供更多学习信号。
- 更好的序列建模:学习令牌间更长程的依赖关系。
- 收敛速度加快:更多监督信号加速训练。